提示集成 Prompt Ensembling
提示集成(Prompt ensemblin)是使用多个不同的提示来尝试回答同一个问题的概念。对此有许多不同的方法
DiVeRSe
DiVeRSe(“推理步骤的多样性验证器”, "Diverse Verifier on Reasoning Steps")是一种以三种方式提高答案可靠性的方法。它通过以下三种方式实现:1)使用多个提示生成多样化的完成结果,2)使用验证器区分好的答案和坏的答案,以及3)使用验证器检查推理步骤的正确性。
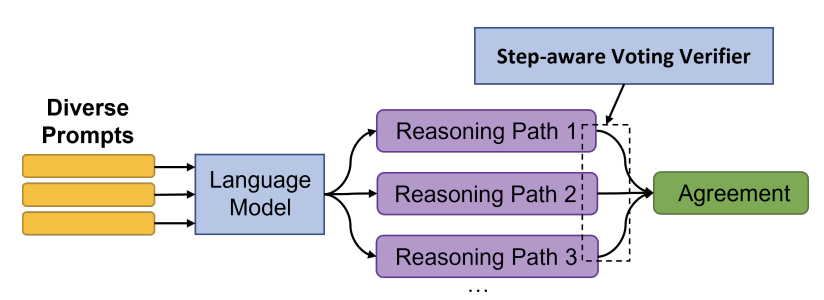
DiVeRSe (Li et al.)
多样化提示
DiVeRSe在给定的输入中使用5个不同的提示。为了构建每个提示,他们从训练集中随机抽取几个示例。这是一个这样的少样本提示(k=2)的示例,其中的示例来自GSM8K基准 2 。在实践中,DiVeRSe在这个基准中使用5个示例来构建提示。
Q: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
A: Natalia sold 48/2 = 24 clips in May.
Natalia sold 48+24 = 72 clips altogether in April and May.
72
Q: Weng earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?
A: Weng earns 12/60 = $0.2 per minute.
Working 50 minutes, she earned 0.2 x 50 = $10.
10
Q: Betty is saving money for a new wallet which costs $100. Betty has only half of the money she needs. Her parents decided to give her $15 for that purpose, and her grandparents twice as much as her parents. How much more money does Betty need to buy the wallet?
A:
在生成了5个类似上述的不同提示后,DiVeRSe为每个提示生成了20个推理路径(温度=0.5)。以下是一些上述提示的示例完成。请注意,答案并不总是正确的。
Betty has 0.5*100 = $50.
Then she gets 15 more = $65.
Then she gets 2*15 = $90.
She needs 100-90 = $10 more.
10
A: Betty has 0.5*100 = $500. Then she gets 15 more = $650. Then she gets 2*15 = $900. She needs 100-90 = $1000 more. #### 1000
目前为止,DiVeRSe已经生成了100个不同的完成结果。
投票验证器 Voting Verifier
现在,我们可以像自洽性那样,采取获得多数票的答案。
然而,DiVeRSe提出了一种更为复杂的方法,他们称之为投票验证器(voting verifier)。
在测试时,使用投票验证器是一个两步骤的过程。首先,验证器(一个神经网络)根据完成度的正确可能性为每个完成度分配一个0-1的分数。然后,“投票”组件将不同答案的所有分数相加,并得出最终答案。
Example
这里有一个小例子。假设我们对于提示What is two plus two? 有以下的完成选项:
4
two + 2 = 5
I think 2+2 = 6
two plus two = 4
<!-- highlight-start -->
It is 5
<!-- highlight-end -->验证者将阅读每个完成的答案并为其分配一个分数。例如,它可能分配的分数分别为:0.9、0.1、0.2、0.8、0.3。然后,投票组件将对每个答案的分数进行求和。
score(4) = 0.9 + 0.8 = 1.7
score(5) = 0.1 + 0.3 = 0.4
score(6) = 0.2最终答案是4,因为它得分最高。
但是验证者是如何接受培训的呢?
But how is the verifier trained?
验证器使用了稍微复杂的损失函数进行训练,这里我不会详细介绍。请阅读论文的第3.3节以获取更多细节。
问我任何问题(AMA)的提示 (AMA Prompting)
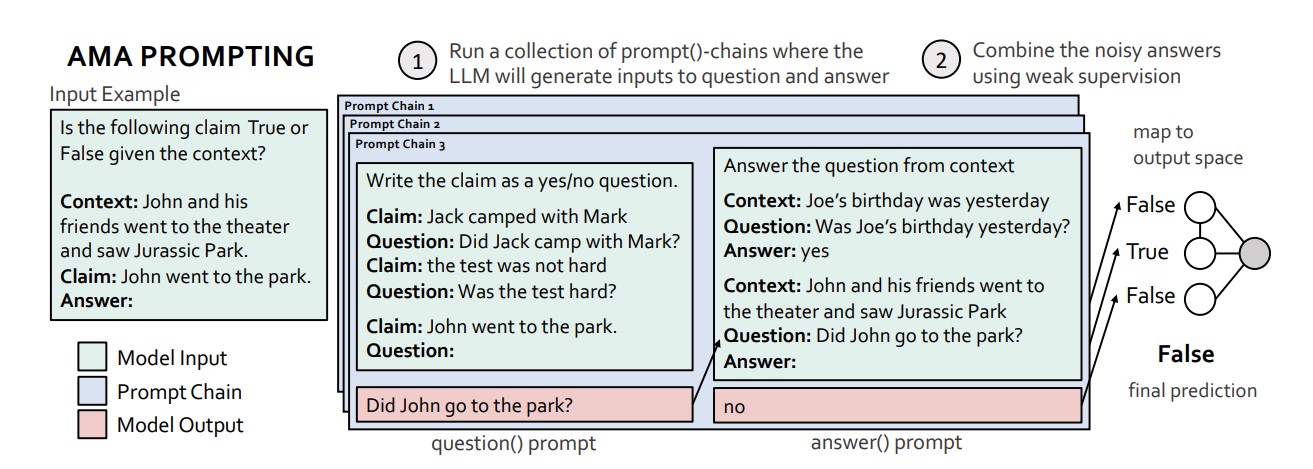
问我任何事(AMA)提示是一种类似于DiVeRSe的方法。然而,它的多个提示步骤和答案聚合步骤都有显著的区别。AMA的核心思想是使用LLM生成多个提示,而不仅仅使用不同的少量示范。
多个提示
AMA显示,你可以采用多种方式重新格式化问题,以创建不同的提示。例如,假设你正在从一堆网站上获取有关动物的信息,并且只想记录那些生活在北美洲的动物。让我们构建一个提示来确定这一点。
假设有维基百科上的以下段落:
The Kermode bear, sometimes called the spirit bear (Ursus americanus kermodei), is a subspecies of the American black bear and lives in the Central and North Coast regions of British Columbia, Canada.
你可以将这个任务格式化成一个提示:
Is the following claim True or False given the context?
Context: The Kermode bear, sometimes called the spirit bear (Ursus americanus kermodei), is a subspecies of the American black bear and lives in the Central and North Coast regions of British Columbia, Canada. Claim: This animal lives in North America
Answer:
这个表达有点奇怪。为什么不直接使用以下更简单的提示呢?
Context: The Kermode bear, sometimes called the spirit bear (Ursus americanus kermodei), is a subspecies of the American black bear and lives in the Central and North Coast regions of British Columbia, Canada.
Question: Does this animal lives in North America?
嗯,通过以这种特殊方式提出问题,我们可以产生不同的提示。我们在这里的第一步是将 This animal lives in North America 这个主张重新格式化为不同的问题,这些问题基本上是在询问同样的事情。为了做到这一点,我们将通过下面图片中的提示来处理这个主张。

这可能会输出:
- Was the animal living in North America?
- Does the animal live in North America?
- Where does the animal live?
这个想法是为了创造任务的不同视角。然后我们将每个视角应用到给定的背景中,就像这样:
Context: The Kermode bear, sometimes called the spirit bear (Ursus americanus kermodei), is a subspecies of the American black bear and lives in the Central and North Coast regions of British Columbia, Canada.
Question: Was the animal living in North America?
Then, we can generate answers for each:
Yes it wasYes it doesNorth America
这些是中间答案。我们需要将它们映射到任务标签(例如是或否)。
我们可以通过将中间答案通过以下提示传递来完成这个任务:
Select the correct category.
"Categories":
- Yes, North America
- No, not North America
"Yes it was" fits category:
现在我们可以得到我们的输出答案。
Yes, North AmericaYes, North AmericaYes, North America
在这里,他们都同意,所以我们可以直接采用第一个答案。然而,如果他们意见不一致,我们可以使用AMA聚合步骤来得出最终答案。
答案汇总
AMA使用了一种非常复杂的策略来汇总答案(比DiVeRSe更复杂),而不仅仅是采用多数答案。为了理解为什么多数答案可能是一个糟糕的选择,考虑我们之前生成的两个问题。
- Was the animal living in North America?
- Does the animal live in North America?
它们非常相似,所以很可能产生相同的结果。由于问题非常相似,它们将有效地对最终结果产生偏见。为了解决这个问题,AMA依靠弱监督和复杂的数学方法来估计它创建的不同提示之间的依赖关系,然后使用这些方法来适当地加权。
所以,对于我们提出的三个问题,可能会分配权重为25%,25%和50%,因为前两个问题非常相似。
尽管AMA的聚合策略非常强大,但它非常复杂,我在这里不会详细介绍。请阅读论文的第3.4节以获取更多细节。
结论
-通过这种提示策略,AMA能够利用GPT-J-6B 超越GPT-3。
- AMA在给出的上下文中包含答案的问题上更好。
总结
集成方法非常强大。它们可以用来提高任何模型的性能,并且可以用来提高模型在特定任务上的性能。
在实践中,多数投票应该是你的首选策略。
相关论文:
- Li, Y., Lin, Z., Zhang, S., Fu, Q., Chen, B., Lou, J.-G., & Chen, W. (2022). On the Advance of Making Language Models Better Reasoners.
- Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., & Schulman, J. (2021). Training Verifiers to Solve Math Word Problems.
- Mitchell, E., Noh, J. J., Li, S., Armstrong, W. S., Agarwal, A., Liu, P., Finn, C., & Manning, C. D. (2022). Enhancing Self-Consistency and Performance of Pre-Trained Language Models through Natural Language Inference.
- Arora, S., Narayan, A., Chen, M. F., Orr, L., Guha, N., Bhatia, K., Chami, I., Sala, F., & Ré, C. (2022). Ask Me Anything: A simple strategy for prompting language models.
- Wang, B., & Komatsuzaki, A. (2021). GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax. https://github.com/kingoflolz/mesh-transformer-jax