四种资料提问
除了直接利用 GPT 预训练时压缩为参数的知识与能力之外,还可以在提问时附加资料给它,从而依据资料进行提问。你可以这么看,我们这时在提示语中附加了资料给模型,它当场「学习」这些知识,然后进行回答。
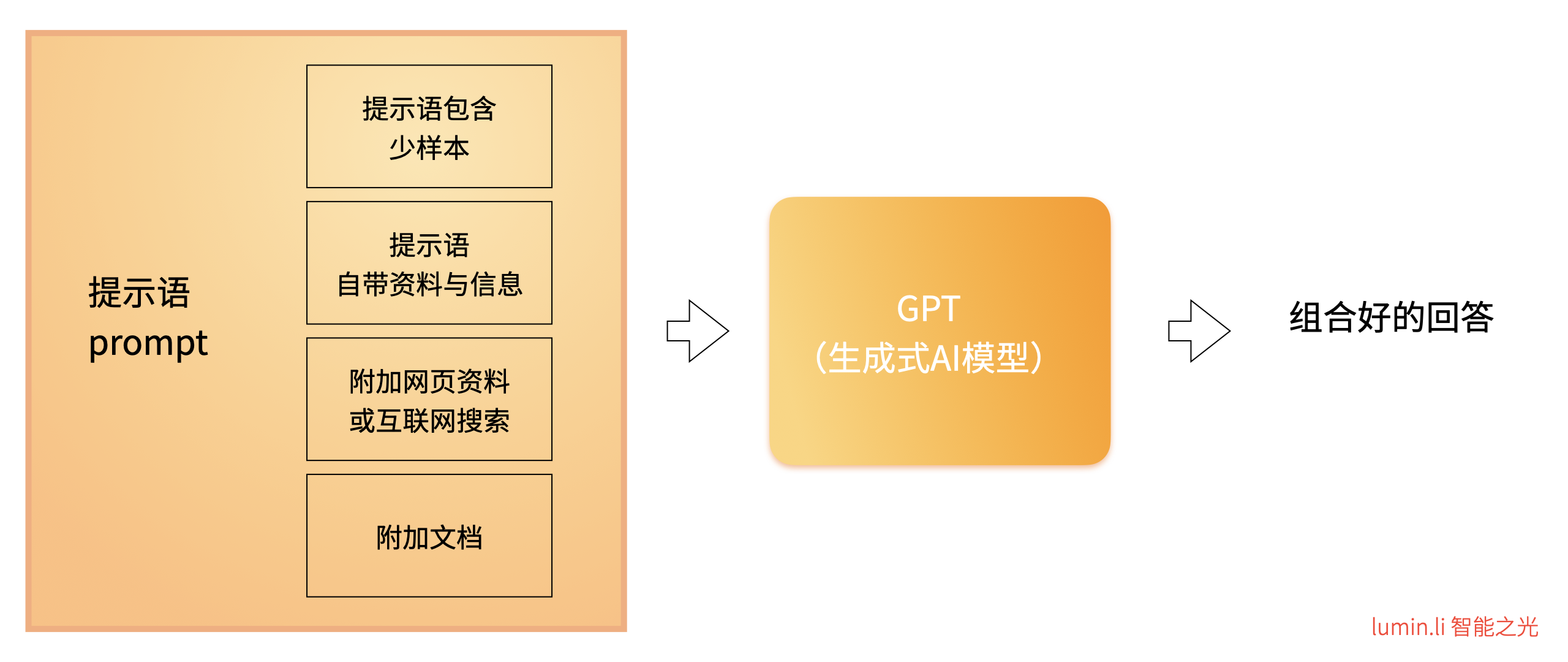
如上图所示,我们将附加资料分成如下四种类型,用四种方式在提问时附加资料,其中前两种是直接将资料与信息附加在提示语中,后两种则通常需要工具的协助:
- 少样本提问
- 附加资料与信息
- 附加网页或采用互联网搜索
- 附加文档
OpenAI 在其《Cookbook》指南中,有一篇文章(link)对比「问题回答」(question answering)与「基于嵌入的搜索」(embedding-based search,即将资料嵌入、进行相似性搜索后作为提问的附加资料),我们在这里所用的方式就是在提问时「将知识插入到输入消息中」。:
GPT可以通过两种方式学习知识:
- 通过模型权重(即,在训练集上微调模型)
- 通过模型输入(即,将知识插入到输入消息中)
它还类比说,模型权重就像是长期记忆。当你对一个模型进行微调时,就像是在一个星期之后的考试中学习。当考试来临时,模型可能会忘记细节,或者误记它从未阅读过的事实。消息输入就像是短期记忆。当你将知识插入到一条消息中时,就像是在考试中带着开放的笔记。有了笔记在手,模型更有可能得出正确的答案。
少样本提问:提问中附加样本
直接提问时,我们没有提供任何样本,因此可被称为「零样本提问」(Zero-shot prompt)。为了在提问时提供知识给AI模型,我们可以附加少量的样本,也称「少样本提问」(few-shot prompt)。研究证明,模型可以快速地从我们所给的知识中学习,从而回答我们的问题,OpenAI的 GPT-3 论文题目为《语言模型是少样本学习者》(link)。
我们来分别看看「零样本提问」与「少样本提问」
「零样本提问」
以下为一个零样本提问示例(来源link):
将文本分类为中性、负面或正面。
文本:我认为这次假期还可以。
情感:
中性
「少样本提问」
例如,我们希望 GPT 能够帮我们判断,微信中发出一句话的人的心情是正面、中性还是负面,我们可以预先给出几个例子,说明如何看其中的表情:通常在微信对话中,抿嘴笑脸表情不应当被解读为正面、而是中性。龇牙笑脸通常为正面。偷笑笑脸为中性,而非负面。当我们这样做了之后,它将能对微信聊天中的话进行更好的判断。
将微信对话分类为中性、负面或正面。
如下示例重点展示,表情(emoji)反映人的心情:
文本:我认为这次假期还可以。🙂 情感:中性
文本:我认为这次假期还可以。😁 情感:正面
文本:我认为这次假期还可以。😂 情感:负面
文本:这个演示还好。😂
情感:
负面
文本:这个演示还好。😎
正面
我们也可以用少样本来告知模型应该采用什么样的格式进行输出。在这几个章节,我们考虑的重点是模型的输入,而稍后会专门讨论如何控制模型的输入格式。这里为讨论少样本提问,我们给出一个示例:
你的任务是从文本中提取关键词。
文本 1:Stripe 为应用开发者提供 API,让他们将付款处理集成到他们的网站和 移动应用程序中。
关键词 1:Stripe、付款处理、API、应用开发者、网站、移动应用程序
**
文本 2:OpenAI 训练了先进的语言模型,非常擅长理解和生成文本。我们的 API 让你可以提供访问这些模型,并可用于解决各类涉及处理语言的任务。
关键词 2:OpenAI、语言模型、文本处理、API。
**
文本 3:
关键词 3:
在上下文直接提供资料
在向 GPT 提问时,我们的提问并非只是可以短短一句话,只要提示语的长度不超过模型上下文窗口的最长限制即可。因此,我们可以在提示语中加入大量的资料。
GPT-3.5的上下文长度为 4096 token(标记符),现在,有些模型的上下文已经在大幅提升,GPT-4 模型提供有一个 3.2 万 Token的版本,而 Anthropic 公司的 Claude 模型提供有一个 10万 Token 的版本,这几乎可以将整本书作为上下文提供给模型。
任务本身的资料
我们要求 AI 模型完成的很多任务其实是本身是需要资料的,比如,当我们要求 GPT 进行文本改写、文本摘要、文本翻译时,我们需要提供相应的文本。
我们通常将大量文本放在分隔符(delimiter)之中,以让模型能更方便地分辨这是上下文信息。通常所用的分隔符是三个英文引号("""),如下述例子所示:
为如下文本编写200字以内的摘要。要求:第一句是总体概要,之后为三个要点。
"""
专家预测的准确度比不上扔飞镖的猴子
人们想当然地从对过去的解读中预测未来,总是忽视“未来是不可预知的”这一观点……
(这里将《思考,快与慢》第20章“专家预测的准确度比不上扔飞镖的猴子”一节的全文提供给了GPT-4模型)
"""
摘要:
这篇文章主要探讨了预测未来的困难性以及专家预测的准确性问题。首先,人们往往过于自信地认为可以通过分析历史趋势来预测未来,然而很多历史事件实际上是由难以预计的因素如运气决定的。其次,尽管社会各界的专家经常被寄希望于给出准确的预测,但研究发现,这些专家的预测准确率并不高,甚至在某些情况下,他们的预测还不如随机抛掷的结果。最后,过多的知识反而可能导致预测者对自己的能力过于自信,从而影响预测的准确性。这篇文章强调,虽然短期预测可能较为准确,但我们应该明白,对于长期未来,高度的不确定性使得准确预测非常困难。
任务所需的参考资料
我们也可以在提问语中附加任务所需的其他资料。例如,在翻译时,我们可以为它提供一个词汇表,要求它按词汇表翻译。
你的任务是将 AI 领域的英文翻译为中文。缩写词和词汇表如下:
"""
缩写词:如下缩写词、组合词不翻译
- GPT, GPU, AI, ChatGPT
词汇表:如下词汇按词汇表翻译(英文词/缩写词/中文词),无中文则表示该词无需翻译
- Large Language Model, LLM, 大语言模型
- Transformer,,转换器
- Generative AI,,生成式AI
- token,,
""""
要翻译的文章:
"""
原文
"""
翻译:
提供知识与信息
你也可以在提示语中给出相应的知识与信息,要求GPT在回答时按它们进行回答。示例如下:

在提问中,我们给出了商业模式画布的九个方格,从而让它遵照我们给出的信息进行分析。当然,你完全可以在上下文长度限制内,提供更为详尽的资料。
问:你是一个商业模式专家,熟悉科技行业、互联网行业。
1997年,乔布斯回归苹果公司。用商业模式画布对当时的苹果公司进行分析、给出战略建议。
商业模式画布的九个方格是:1、客户细分;2、价值主张;3、用户获取渠道;4、客户关系;5、收益流;6、核心资源;7、催生价值的核心活动;8、重要合伙伙伴;9、成本架构。
回复要求:先一句话概括当时苹果公司的情况,然后用商业模式画布分析它当时的情况(仅讨论客户细分、价值主张与催生价值的核心活动,给出具体的案例),最后给当时的苹果公司三点战略建议。回复做到简洁明了,采用列表格式。
附加网页资料或互联网搜索
在 ChatGPT 推出时,它不能访问互联网,因此附加的资料的方法只能是在提示语中直接添加。
微软推出的新必应(New Bing)则为模型附加了进行互联网搜索的能力。之后,随着 ChatGPT 插件的推出,采用第三方插件 Webpilot 让 ChatGPT 也可以访问互联网,从而使用互联网上的资料。
我们先来看看互联网搜索和向模型提问的结合。
搜索型提问
当我们使用微软新必应(bing.com/chat)时,它会在互联网上进行搜索,然后综合网页结果,用AI模型给出回答。
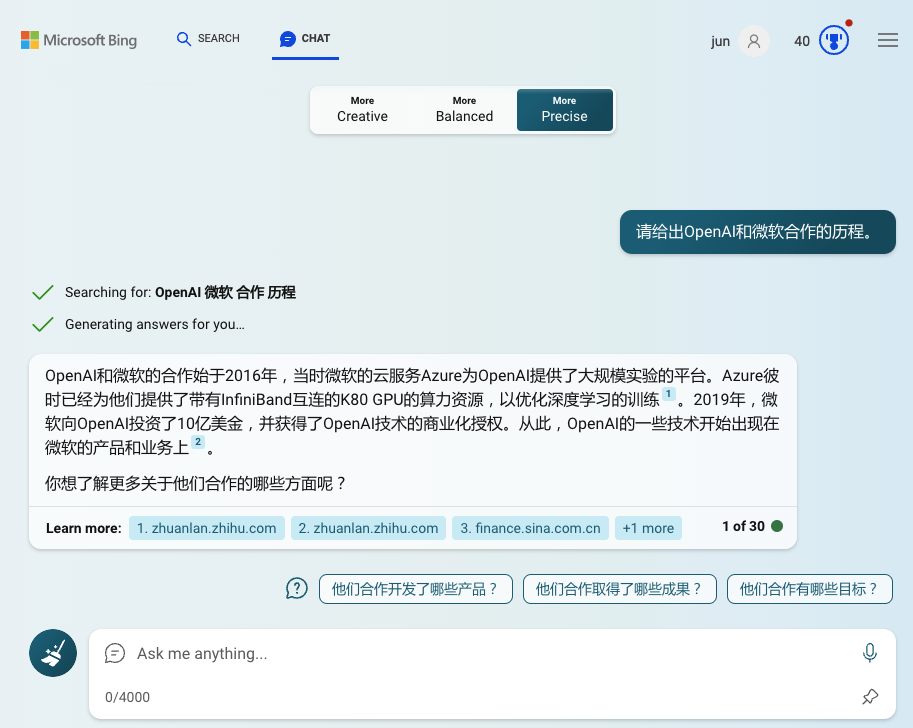 (2023年6月12日提问)
(2023年6月12日提问)
在如上提问中,我们选择了「更精确」的选项,这会让回答尽量忠实于搜索结果资料。你也可以看到,它的回答中,分别引用了两个来源。
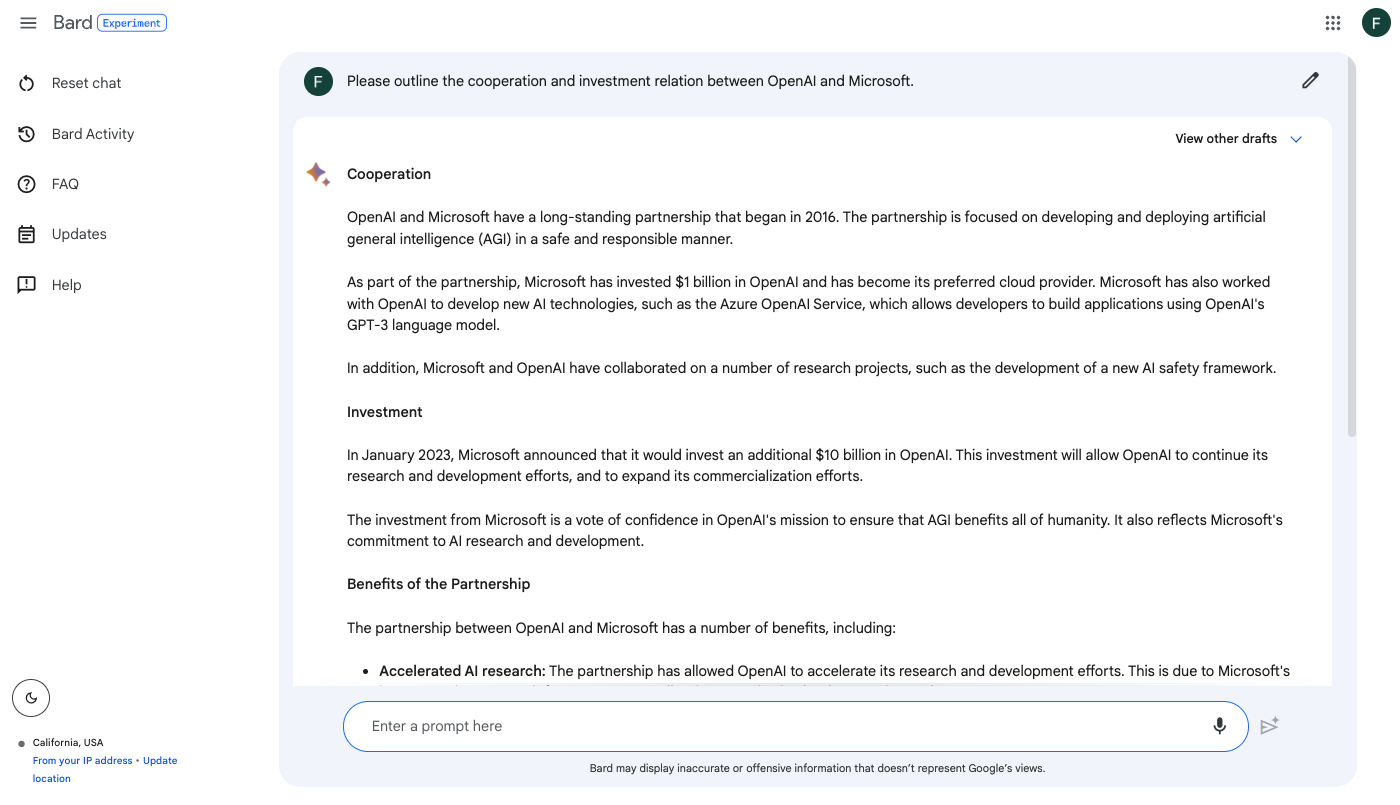
类似地,我们也可以向谷歌的聊天机器人 Bard (bard.google.com)提问。由于它暂时还不支持中文,我们采用英文提问,回答如下:
WebPilot 访问网页
在 ChatGPT ,我们可以使用 WebPilot 插件访问网页。ChatGPT Plus 用户在使用 GPT-4 模型,可以安装相应的插件。如下是 WebPilot 的自我介绍:
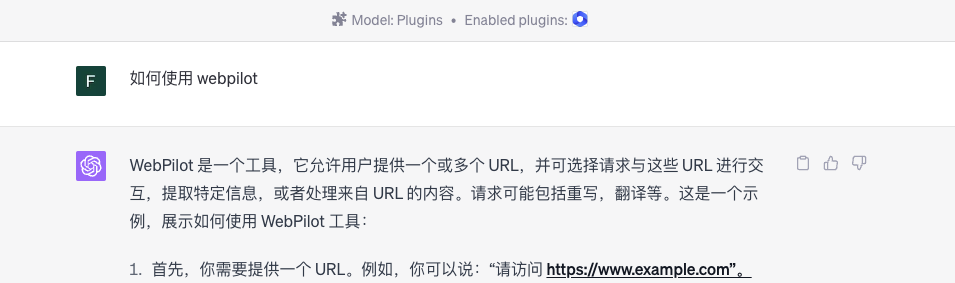
使用 Webpilot 插件,我们可以将一个网页作为提问的上下文资料。当然,你也可以将自己的内容放到一个新网页中,从而将这些内容作为提问的上下文资料。
在使用过程中,你会看到它的步骤:首先,它使用这个插件获取资料。然后,插件将获得的资料作为上下文,模型对我们的提问进行回答。
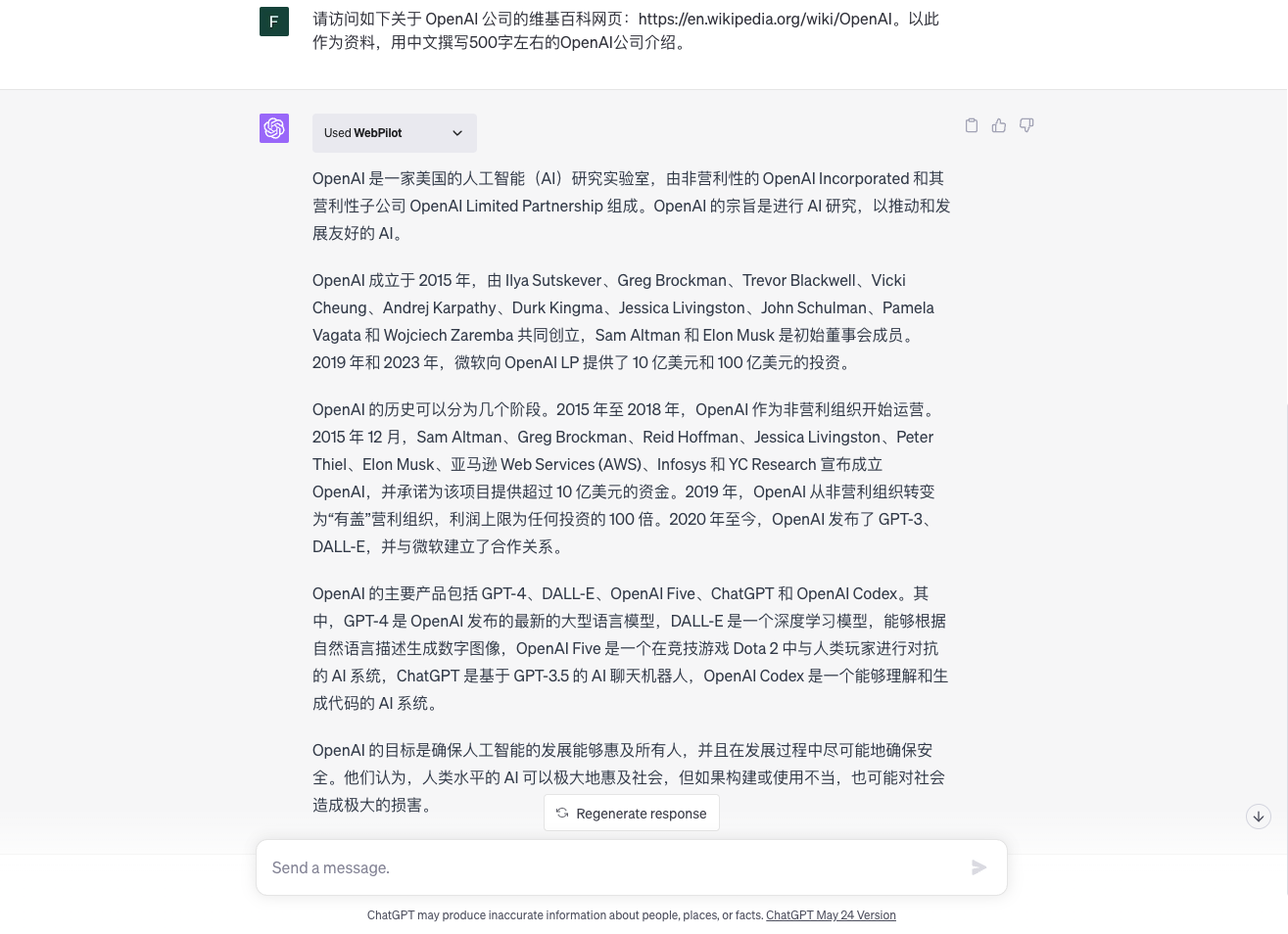
这解决了 GPT-4 的资料仅限于2021年9月之前的问题。如下是一个用维基百科资料作为资料的示例,我们用英文维基百科的 OpenAI 页面作为上下文,要求它用中文进行回答。
请访问如下 OpenAI 维基网页:https://en.wikipedia.org/wiki/OpenAI。
以此作为资料,用中文撰写500字左右的OpenAI公司介绍。
与文档对话
在各种工具的协助下,我们还可以将整个文档作为附加资料,用 AI 模型与文档对话。
文档对话的实质
与文档对话时,我们并不是将文档本身提交给GPT。实际上这些工具在背后做的是:它将文档中的文本提取出来、打散为碎片(片段),然后用提问与这些碎片进行相似性比较,选取相关的少量片段作为提问的上下文。
目前,通常的做法是将文本片段嵌入为高维向量,存入向量数据库,然后进行相似查询。
ChatPDF 与文档对话
 ChatPDF首页(采用 google translate 进行翻译)
ChatPDF首页(采用 google translate 进行翻译)
ChatPDF 是一个第三方服务,我们可以上传PDF文档,与文档进行对话。以下是对话示例截图,它的回答会给出相应的PDF页面作为参考,图中数字3就表示该内容出现在第三页:
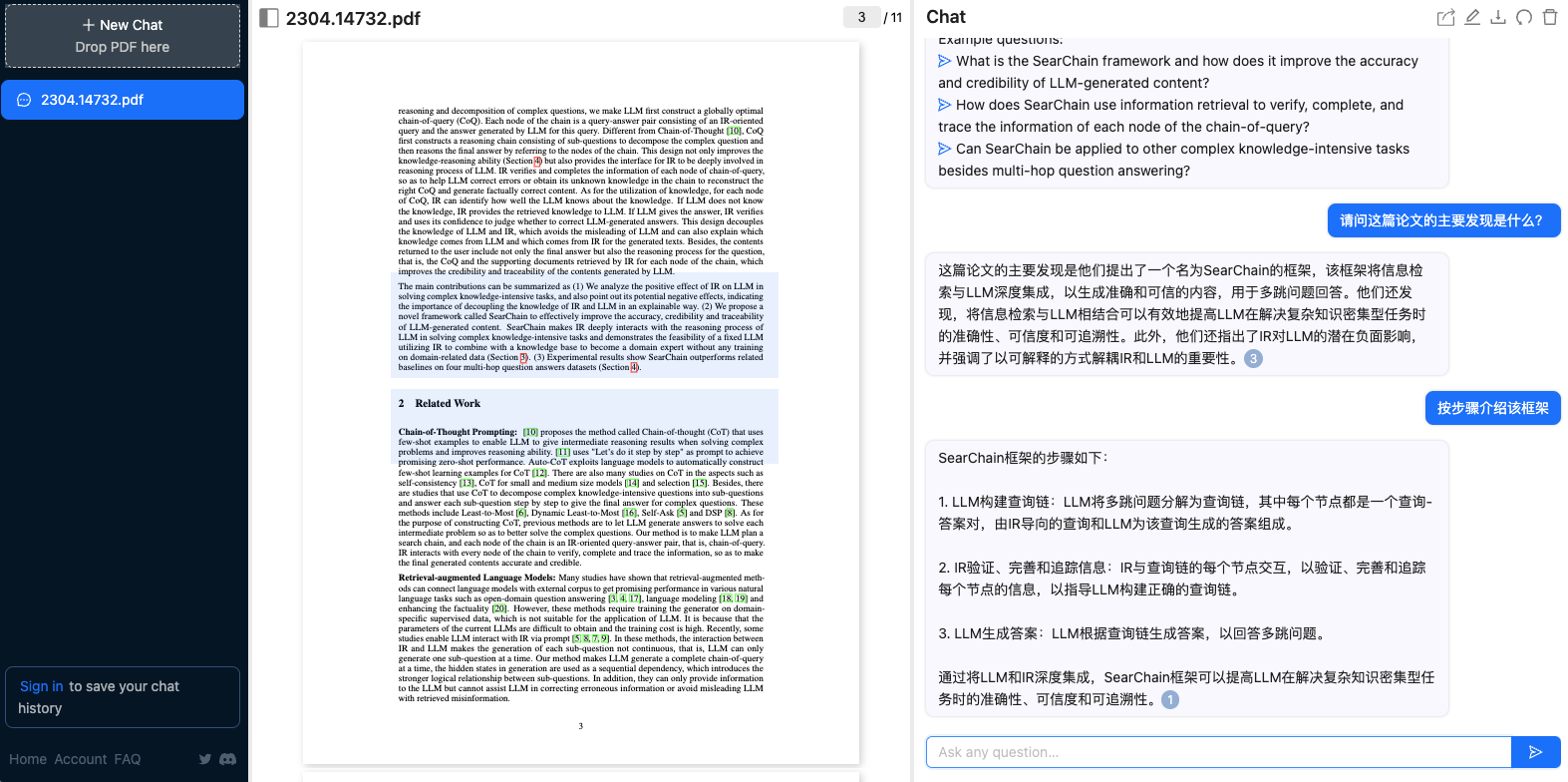
请问这篇论文的主要发现是什么?
这篇论文的主要发现是他们提出了一个名为SearChain的框架,该框架将信息检索与LLM深度集成,以生成准确和可信的内容,用于多跳问题回答。他们还发现,将信息检索与LLM相结合可以有效地提高LLM在解决复杂知识密集型任务时的准确性、可信度和可追溯性。……
ChatGPT 文档插件
ChatGPT 中有很多文档插件,有的功能与 ChatPDF 类似是与单一文档对话,有的则能在文档库中搜索。
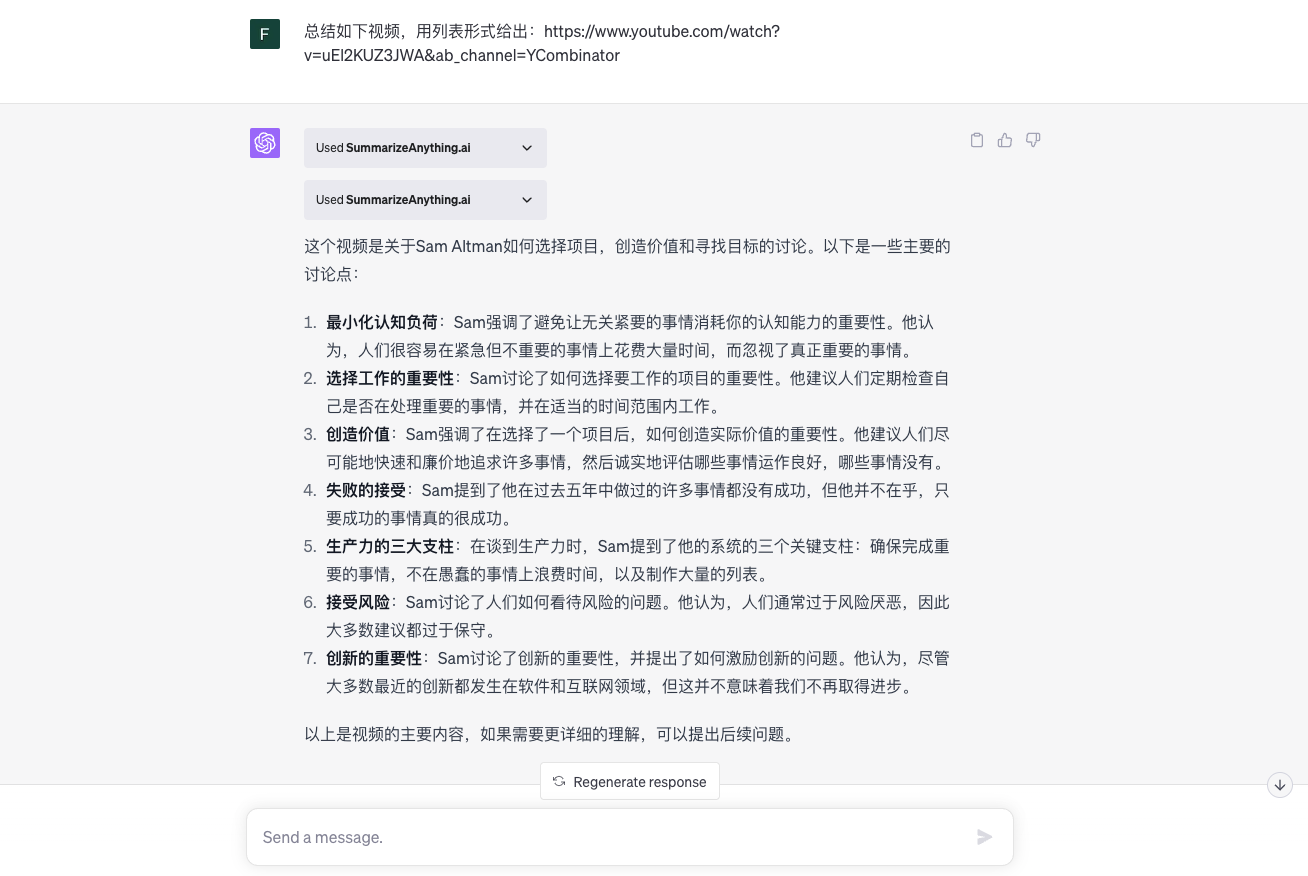
值得注意的,文档并不一定是 PDF 或文本格式,也可以是视频。这里,我们来看看「SummarizeAnything.ai」这个插件,它能够对Youtube视频、网页、PDF文档生成摘要。