用 LangChain 与模型交互
目录
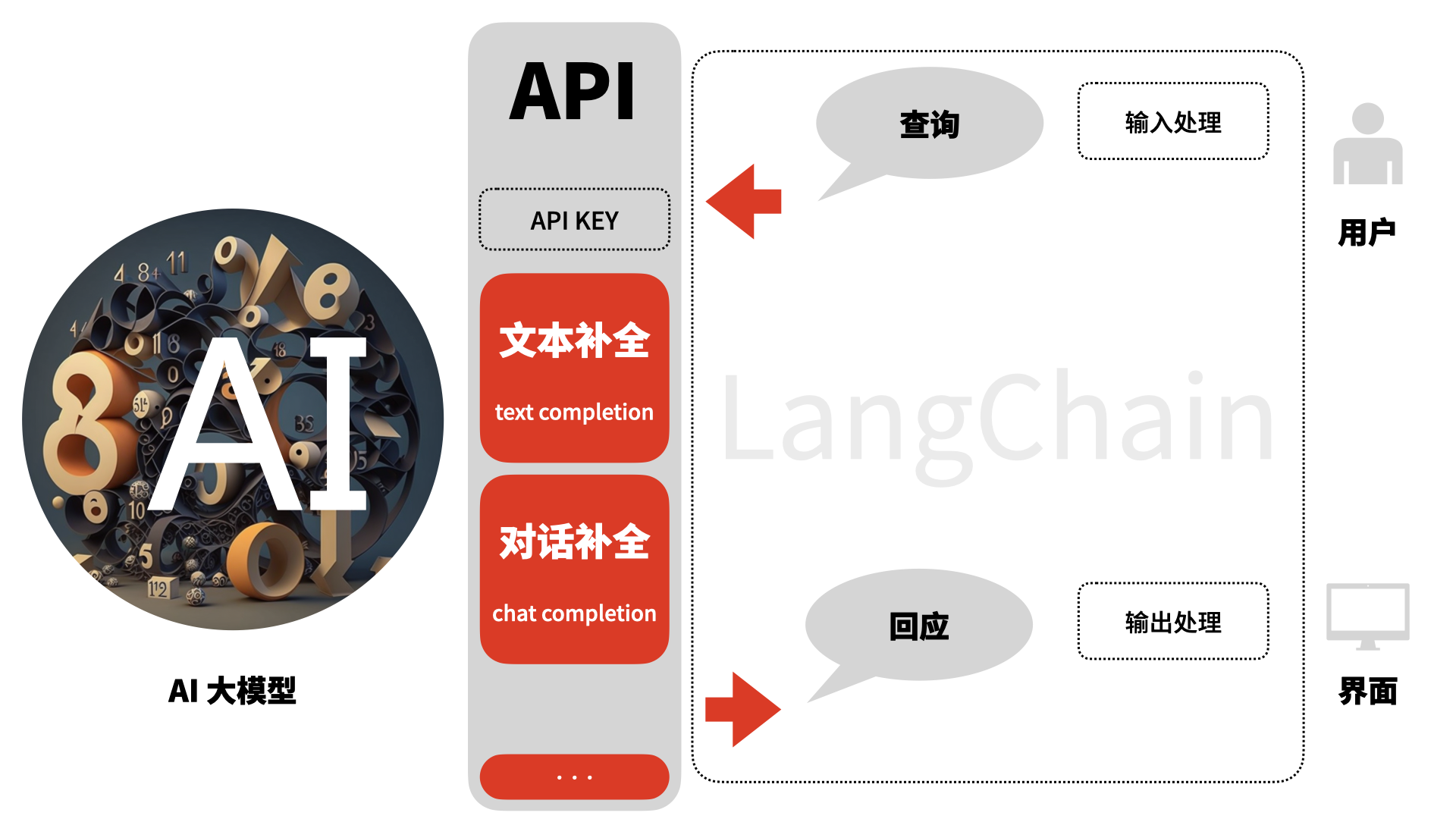
从本篇开始,我们将实际使用 LangChain 搭建 AI 应用。如图所示,与普通应用不同,AI 应用是向 AI 大语言模型提交查询,并处理得到的回应。
1. 与 AI 大语言模型交互基础
1.1 对话补全接口
我们通常用 API 访问大模型,这些大模型可能是云服务的形式,也可能是本地运行的。自2023年以来,通常多数 AI 大语言模型的 API 都兼容 OpenAI 的 API 规格。一般来说,现在有两类常用的 API 接口:
- 文本补全(text completion);
- 对话补全(chat completion);
对话补全是 2023 年初 OpenAI 推出的,目前已经实际成为主要的 API 接口。在 OpenAI 文档中,文本补全接口已被归类为过往接口(legacy)。在接下来的讨论中,我们将主要使用对话补全 API 接口。
使用对话补全 API 时,我们向模型输入的是一个消息数组,而得到的是一个 Response 类型。

我们输入模型的消息数组是:
json
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]我们得到的对话消息是:
json
{
"role": "assistant",
"content": "\n\nHello there, how may I assist you today?"
}可点击查看用 Python SDK 调用模型的完整调用与回应。代码摘自 OpenAI API reference。
用 SDK 调用模型接口
python
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)模型接口的完整回应
json
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"model": "gpt-3.5-turbo-0613",
"system_fingerprint": "fp_44709d6fcb",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "\n\nHello there, how may I assist you today?",
},
"logprobs": null,
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21
}
}如上图所示,聊天模型中包括三个角色:系统(system),用户(user),AI 助理(assistant)。在 LangChain 中,它对这三个角色进行了封装:
- SystemMessage langchain docs
- HumanMessage langchain docs
- AIMessage langchain docs
从这个细节我们可以看到,LangChain 的封装可以让我们更方便地在多模型之间切换。
1.2 模型 I/O 简介
LangChain 将与模型调用有关的部分均被纳入其 「Model I/O 模块」」,它绘制如下图示:
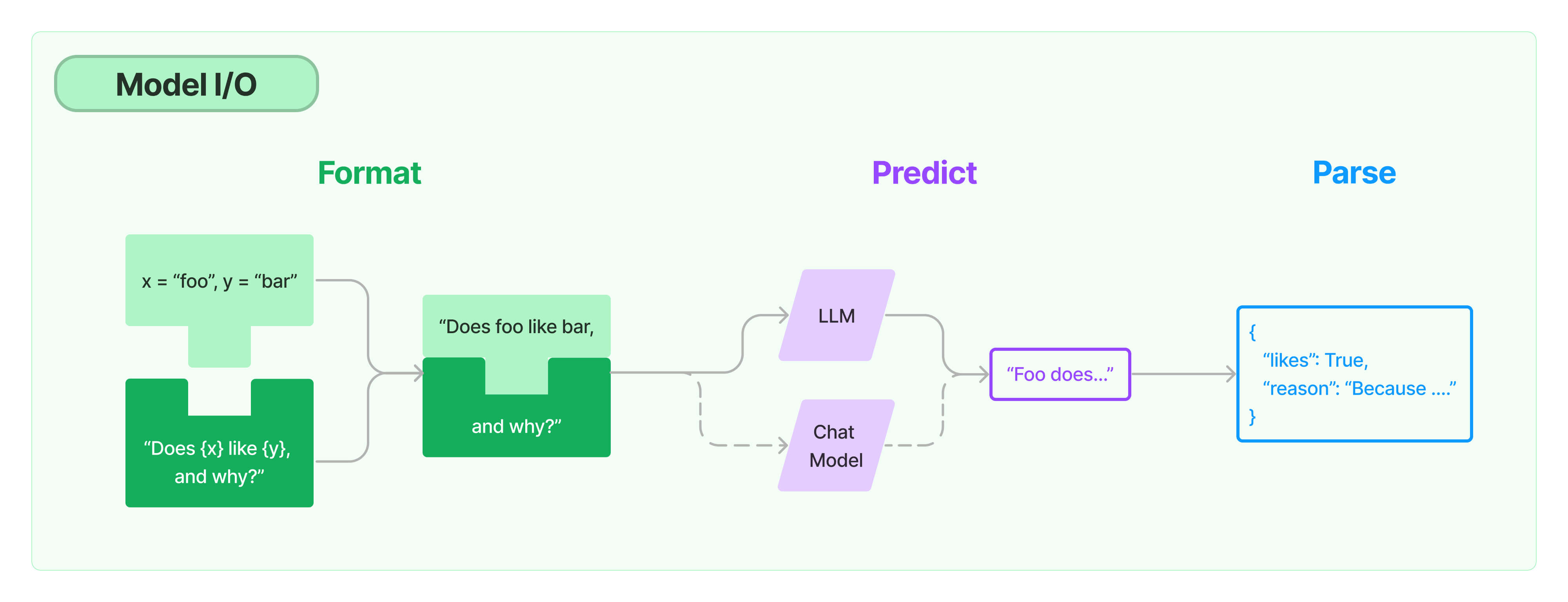
来源:LangChain Docs link
由图中,我们可以看到,一次模型调用通常由如下流程组成:
- Format,用提示语模板与用户提问组合成提示语;
- Predict,将提示语提交模型,模型进行预测;
- Parse,得到模型的回应后,解析并输出。
我们先来简单看下其中 Pridict 部分:我们调用一个 ChatModel,调用invoke(),得到其返回的 AIMessage。
python
from langchain_openai import ChatOpenAI
chatmodel = ChatOpenAI()
chatmodel.invoke("what's generative ai?")模型的返回:
python
AIMessage(content="Generative AI is ...")1.3 设置模型的参数
在以上模型调用中,我们未做任何设置,使用了多个缺省参数(langchain docs, openai docs):
- param openai_api_key (alias
api_key,使用环境变量OPENAI_API_KEY) - param model_name,缺省值为
'gpt-3.5-turbo' - param streaming,缺省值为
False - param temperature,缺省值为
0.7
常用参数还有max_tokens,它可用来控制输出的 token 数量。比如在如下示例中,我们将它设为 30,这将导致消息较长时被截断。
python
from langchain_openai import ChatOpenAI
chatmodel = ChatOpenAI(
temperature=0.0,
max_tokens=30,
streaming=True)
chatmodel.invoke("what's generative ai?")输出结果为:
AIMessage(content='Generative AI refers to a type of artificial intelligence that is capable of generating new content, such as images, text, music, or even videos,')
2. 提示语模板与输出处理
2.1 使用 LCEL 组成调用链
在快速入门中,我们已经初步了解了用 LangChain Expression Language(LCEL)来形成调用链。
python
chain = prompt_template | chatmodel | output_parser其中,调用链chain由三个步骤顺序连接而成:
- 提示语模板
- 大模型
- 输出解析
展开查看完整示例代码
python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
chatmodel = ChatOpenAI()
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are world class technical documentation writer."),
("user", "{query}")
])
output_parser = StrOutputParser()
chain = prompt_template | chatmodel | output_parser
output = chain.invoke({"query": "what's generative ai?"})
print(output)其中,invoke()的参数是整个调用链的输入:{"query": "what's generative ai?"}。
我们采用StrOutputParser (docs)将 AIMessage 转换成 string。
2.2 输出解析器及输出JSON
LangChain-Core 和 LangChain 提供了一系列输出解析器。这是使用 LangChain 相比于直接使用 各模型的 SDK 的一个独特优势。
LangChain-Core 的输出解析器类包括:
output_parsers.base.BaseGenerationOutputParseroutput_parsers.base.BaseLLMOutputParseroutput_parsers.base.BaseOutputParseroutput_parsers.json.JsonOutputParseroutput_parsers.json.SimpleJsonOutputParseroutput_parsers.list.CommaSeparatedListOutputParseroutput_parsers.list.ListOutputParseroutput_parsers.list.MarkdownListOutputParseroutput_parsers.list.NumberedListOutputParseroutput_parsers.string.StrOutputParseroutput_parsers.transform.BaseCumulativeTransformOutputParseroutput_parsers.transform.BaseTransformOutputParseroutput_parsers.xml.XMLOutputParser
LangChain 的输出解析器类包括:
output_parsers.boolean.BooleanOutputParseroutput_parsers.combining.CombiningOutputParseroutput_parsers.datetime.DatetimeOutputParseroutput_parsers.enum.EnumOutputParseroutput_parsers.fix.OutputFixingParseroutput_parsers.openai_functions.JsonKeyOutputFunctionsParseroutput_parsers.openai_functions.JsonOutputFunctionsParseroutput_parsers.openai_functions.OutputFunctionsParseroutput_parsers.openai_functions.PydanticAttrOutputFunctionsParseroutput_parsers.openai_functions.PydanticOutputFunctionsParseroutput_parsers.openai_tools.JsonOutputKeyToolsParseroutput_parsers.openai_tools.JsonOutputToolsParseroutput_parsers.openai_tools.PydanticToolsParseroutput_parsers.pandas_dataframe.PandasDataFrameOutputParseroutput_parsers.pydantic.PydanticOutputParseroutput_parsers.regex.RegexParseroutput_parsers.regex_dict.RegexDictParseroutput_parsers.retry.RetryOutputParseroutput_parsers.retry.RetryWithErrorOutputParseroutput_parsers.structured.ResponseSchemaoutput_parsers.structured.StructuredOutputParseroutput_parsers.yaml.YamlOutputParser
例如,我们可以要求模型 API 输出 JSON 格式。一个示例如下(来源 LangChain Docs)
首先,我们用 Pydnatic 定义一个对象:
python
# 用 Pydantic 定义输出的 JSON 格式
from langchain_core.pydantic_v1 import BaseModel, Field
# Define your desired data structure.
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")然后,我们调用模型,并指示模型输出 JSON 格式:
python
from langchain_core.output_parsers import JsonOutputParser
from langchain.prompts import ChatPromptTemplate
chatmodel = ChatOpenAI()
# And a query intented to prompt a language model to populate the data structure.
joke_query = "Tell me a joke."
# Set up a parser + inject instructions into the prompt template.
parser = JsonOutputParser(pydantic_object=Joke)
prompt_template = ChatPromptTemplate.from_messages(
[
("system", "Answer the user query.\n{format_instructions}"),
("user", "{query}")
])
chain = prompt_template | chatmodel | parser
#print(parser.get_format_instructions())
chain.invoke(
{"query": joke_query,
"format_instructions": parser.get_format_instructions()
})输出的结果为我们定义的 JSON Schema:
json
{
'setup': "Why don't scientists trust atoms?",
'punchline': "Because they make up everything!"
}展开查看 get_format_instructions() 详解
代码中,get_format_instructions()将 Pydantic 对象转换成如下格式指令:
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]} the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
{"properties": {"setup": {"title": "Setup", "description": "question to set up a joke", "type": "string"}, "punchline": {"title": "Punchline", "description": "answer to resolve the joke", "type": "string"}}, "required": ["setup", "punchline"]}
2.3 让大模型流式输出
多数模型 API 现在都提供流式输出(streaming)。
当我们设定 streaming=False 时,API 将在生成所有的内容后再给出回应;而设定 streaming=True时,API 将按 token 逐个地给出回应,而我们接收到后也逐渐地将它在界面上呈现出来。
你可以按如下方式在 Notebook 中尝试
python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
chatmodel = ChatOpenAI(
streaming=True
)
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are world class technical documentation writer."),
("user", "{query}")
])
output_parser = StrOutputParser()
chain = prompt_template | chatmodel | output_parser
response = chain.stream({"query": "what's generative ai?"})
for value in response:
print(value, end='', flush=True)与之前的代码,有如下变化:
- 将模型设为流式输出;
- 调用采用
stream()而非invoke(); - 从开始接收到输出时就逐一打印。
其中,我们采用print(value, end='', flush=True)将输出逐字打印输出。其中,end=''使得后续的输出会紧接着前面的输出;flush=True意味着每次print调用后,输出缓存都会被清空,确保value被直接显示。
LangChain 提供的流式输出机制,让我们可以将整个调用链保持流式状态,便于更方便地组合形成自己的应用。
JSON 格式的流式输出
在前一部分中的 JSON 输出中,我们也可以让它流式输出,代码和结果如下:
python
response = chain.stream(
{"query": joke_query,
"format_instructions": parser.get_format_instructions()})
for s in response:
print(s)结果:
{}
{'setup': ''}
{'setup': 'Why'}
{'setup': 'Why don'}
{'setup': "Why don't"}
{'setup': "Why don't scientists"}
{'setup': "Why don't scientists trust"}
{'setup': "Why don't scientists trust atoms"}
{'setup': "Why don't scientists trust atoms?"}
{'setup': "Why don't scientists trust atoms?", 'punchline': ''}
{'setup': "Why don't scientists trust atoms?", 'punchline': 'Because'}
{'setup': "Why don't scientists trust atoms?", 'punchline': 'Because they'}
{'setup': "Why don't scientists trust atoms?", 'punchline': 'Because they make'}
{'setup': "Why don't scientists trust atoms?", 'punchline': 'Because they make up'}
{'setup': "Why don't scientists trust atoms?", 'punchline': 'Because they make up everything'}
{'setup': "Why don't scientists trust atoms?", 'punchline': 'Because they make up everything!'}
3. 使用 OpenAI SDK 调用其他兼容模型
现在,不少模型提供完全兼容 OpenAI 的 API 接口,从而让开发者可以直接用 OpenAI SDK 调用。如前所述,LangChain 调用 OpenAI 接口时实际上用的是其 SDK,因此,在 LangChain 中我们可以用如下的方式调用模型。
3.1 完全兼容的模型示例:DeepSeek
有些模型选择了完全兼容 OpenAI SDK,我们可以采用更改 openai_api_base (alias base_url)和model_name来调用这些模型。
以 Deepseek 为例(link),它的调用参数包括三项:
base_url:"https://api.deepseek.com/v1"api_key:<deepseek api key>model_name:"deepseek-chat"
调用示例代码如下:
python
from langchain_openai import ChatOpenAI
api_key = userdata.get('deepseek')
base_url= 'https://api.deepseek.com/v1'
model_name='deepseek-chat'
chatmodel = ChatOpenAI(
base_url=base_url,
api_key=api_key,
model_name=model_name)
chatmodel.invoke("what's generative ai?")3.2 需略加处理的模型示例:Zhipu AI
有的模型 API 在鉴权方面有所不同,需要有额外的处理步骤。以 Zhipu AI 为例,它的鉴权采用 JWT 方式,其中 payload 包括三个部分(Zhipu AI docs):
{"api_key":{ApiKey.id},"exp":1682503829130, "timestamp":1682503820130}
api_key: 属性表示用户标识 id,即用户API Key的{id}部分exp: 属性表示生成的JWT的过期时间,客户端控制,单位为毫秒timestamp: 属性表示当前时间戳,单位为毫秒
Zhipu AI 的API Key呈现这样的格式:
'27b735a3c00000000000000.sriaaaaaaaa'
我们需要专门定义一个函数generate_token(apikey, exp_seconds),按其要求生成相当于 api_key 的鉴权参数,然后再调用时使用。
展开查看用 Zhipu API Key生成鉴权参数的函数
python
# source: zhipuai docs https://open.bigmodel.cn/dev/api#nosdk
import time
import jwt
def generate_token(apikey: str, exp_seconds: int):
try:
id, secret = apikey.split(".")
except Exception as e:
raise Exception("invalid apikey", e)
payload = {
"api_key": id,
"exp": int(round(time.time() * 1000)) + exp_seconds * 1000,
"timestamp": int(round(time.time() * 1000)),
}
return jwt.encode(
payload,
secret,
algorithm="HS256",
headers={"alg": "HS256", "sign_type": "SIGN"},
)之后,我们可以这样来调用:
python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
base_url= "https://open.bigmodel.cn/api/paas/v4/"
api_key = generate_token(zhipuai_api_key, 100)
llm = ChatOpenAI(base_url=base_url,
api_key =generate_token(zhipuai_api_key, 100),
model_name='glm-4')
prompt = ChatPromptTemplate.from_messages([
("system", "You are world class technical documentation writer."),
("user", "{input}")
])
output_parser = StrOutputParser()
chain = prompt | llm | output_parser
output = chain.invoke({"input": "what's generative ai?"})
print(output)
# result: Generative AI refers to ……4. 使用 LangChain 调用其他非兼容模型
有很多模型的 API 并不与 OpenAI 兼容,LangChain 中提供了对多种模型的集成,让我们也可以方便地调用这些模型。
以下以百度千帆上的模型为例,百度千帆是百度智能云的 AI 云服务平台,将包括百度文心、Llama、Baichuan、Yi 等各类模型封装成 API 供调用。使用它时,我们要使用 Qianfan SDK。LangChain 对应的文档见:LangChain Baidu Qianfan 。
4.1 调用前的准备(百度文心一言)
在调用前,你需要
- 注册百度千帆账号,开启相关的模型服务,并充值。你需要获得 API KEY 与 API Secret。我们这里配置的是百度文心(ErnieBot)模型。
- 安装 Qianfan SDK:
!pip install langchain --quiet
!pip install qianfan --quiet- 将 API KEY、API Secret 设为环境变量。你可以在创建模型实例时直接提供。
python
os.environ["QIANFAN_AK"] = qf_api_key
os.environ["QIANFAN_SK"] = qf_secrect_key4.2 调用对话补全API
创建对话补全调用的实例:
python
from langchain_community.chat_models.baidu_qianfan_endpoint import QianfanChatEndpoint
chat = QianfanChatEndpoint(
qianfan_ak = qf_api_key,
qianfan_sk = qf_secrect_key,
)调用与结果
python
from langchain.schema import HumanMessage
chat([HumanMessage(content="hello there, who are you?")])AIMessage(content='你好,我是百度研发的知识增强大语言模型,中文名是文心一言,英文名是ERNIE Bot。我能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。如果你有任何问题,请随时告诉我。', additional_kwargs={'id': 'as-6vseajikda', 'object': 'chat.completion', 'created': 1707217164, 'result': '你好,我是百度研发的知识增强大语言模型,中文名是文心一言,英文名是ERNIE Bot。我能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。如果你有任何问题,请随时告诉我。', 'is_truncated': False, 'need_clear_history': False, 'usage': {'prompt_tokens': 7, 'completion_tokens': 57, 'total_tokens': 64}})
在这里,我们调用的 endpoint 地址是:/chat/eb-instant。
4.3 调用文本补全API
python
from langchain_community.llms import QianfanLLMEndpoint
llm = QianfanLLMEndpoint(streaming=True)
res = llm("hi")
print(res)返回结果是:
你好,有什么我可以帮助你的吗?
在这里,我们调用的 endpoint 地址同样是:/chat/eb-instant。但可以看出调用的是文本补全API。
5. 小结
在本教程中,我们学习了如何使用 LangChain 调用模型,一方面,我们了解如何使用提示语模板、输出解析器、流式输出,另一方面我们了解了如何用 LangChain 调用 OpenAI 之外的其他模型。