RAG:检索增强生成
目录
1. RAG 简介
1.1 什么是 RAG
所谓检索增强生成(Retrieval Augment Generation, RAG)指,当用户提出一个问题时,AI 应用先去知识库中检索出一定数量的文档片段,然后将问题与文档片段一起提交给 AI 大语言模型,由模型生成回应。如图所示。
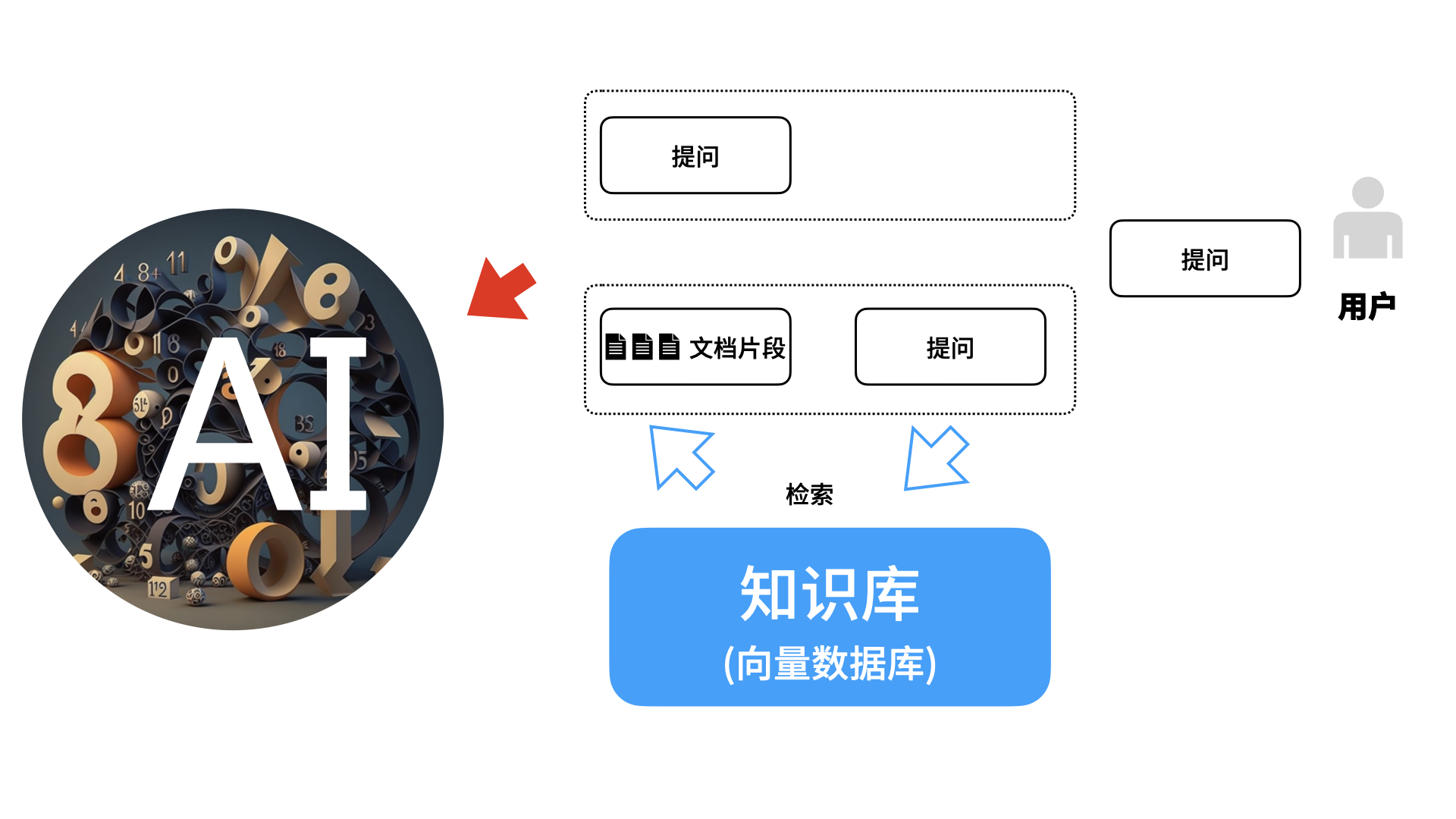
经过预训练与微调的大模型已经掌握了数据与知识,但是,通过将与问题相关的文档片段作为上下文在提示语中提交给模型,它能生成出与知识库更匹配的内容。当我们需要对模型生成时所参考的知识有更明确的控制时,我们也会选择使用 RAG。
RAG 是将知识提交给 AI 模型的一种方式。OpenAI 在一份文档中就做了一个类比——开卷考试 vs 闭卷考试。通过精调(fine-tune)将知识提交给模型,然后再用精调过的模型参数生成,这相当于学习后的闭卷考试;而通过 RAG 将知识在提示语中提交给模型,这相当于开卷考试。
通常来说,如果我们希望模型针对一个特定知识库来生成,RAG 是更便捷的方式。以写作为例,精调能够通过样本来让模型学会某种风格,而 RAG 则可以让模型直接引用知识库中的语句。
对于 RAG,最终用户和开发者的视角是不同:
- 普通用户,他们使用一个带有知识库的 AI 应用,他们的每次提问都在幕后先进行知识库的检索,然后再由大模型进行回答。
- 高阶用户,他们会上传文档(比如对话里上传PDF、GPTs中上传文档作为知识库),然后针对自己上传的文档或知识库进行问答。
- 应用开发者的关注点则包括另一面,即要考虑如何将文档转换为可供检索的知识库,并确保检索出的内容是相关的。
在讨论 RAG 时我们经常同时提及各类向量数据库,它是开发者存放经文本嵌入处理成向量的知识的仓库。要注意的是,除了利用文本嵌入的相似性检索之外,我们也可以结合关键词搜索等多种方式来检索。
1.2 文本嵌入与检索
在有了如上背景讨论后,我们再来看 LangChain 的 RAG (其称「Retrieval 模块」)。它为开发者提供将文档转换为可检索的知识库的功能。对比而言,LlamaIndex 库则为文本检索提供了更多的方式。
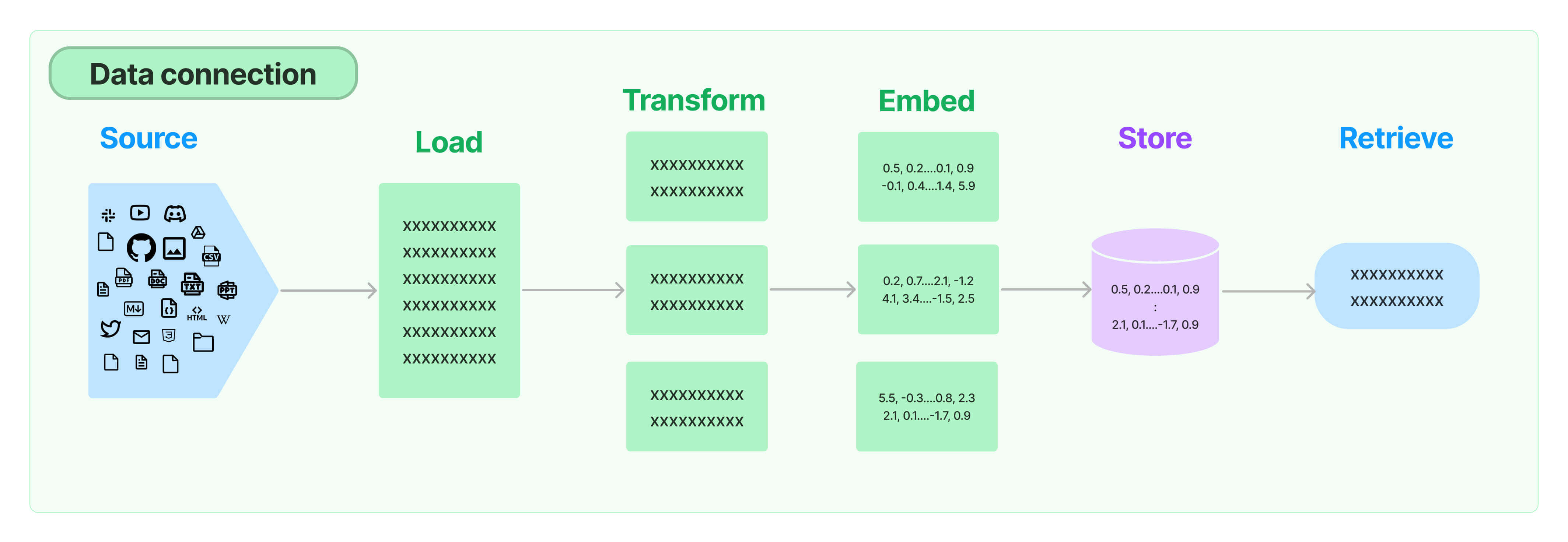 来源:LangChain 检索模块,LangChain Docs
来源:LangChain 检索模块,LangChain Docs
如上图所示,我们可以看到,开发者要经过如下步骤来将文档变成知识库:
- 加载(Load),比如加载 PDF、epub、API接口等。
- 转换(Transform),比如将长文档切分为较小的片段。
- 嵌入(Embed),采用 AI 模型将文档片段转换为向量。
- 存入向量库(Store),用各类向量数据库将向量存储起来,以备后续检索。
这是 RAG 的索引阶段,在用户使用时,则进入到 RAG的检索阶段。也即,RAG 包括两个阶段:
索引阶段:知识库的形成,包括如上四个环节;
检索阶段:知识库的检索,可采用多种检索策略。
LangChain 的检索模块为如上两个阶段都提供了丰富的支持。
1.3 RAG 简单示例
在之前的教程中,我们介绍了一个 RAG 示例。其中,使用Chroma 向量库做示例。嵌入我们使用的是 OpenAI 的 embedding 服务。
第一阶段(索引):文本嵌入 Embedding
我们将两段文本进行嵌入,并存入vectorstore。
python
from langchain_community.vectorstores import Chroma
from langchain_openai.embeddings import OpenAIEmbeddings
vectorstore = Chroma.from_texts(
["harrison worked at kensho", "bears like to eat honey"],
embedding=OpenAIEmbeddings(),
)如上这几行就是完成了「知识库的形成」,将"harrison worked at kensho"、"bears like to eat honey"转换为向量,然后存入chroma 向量库。
第二阶段(检索):用户提问-检索文本-模型回答
在第二阶段,我们先将向量库作为 retriever。
python
retriever = vectorstore.as_retriever()然后再根据用户提问检索调用。调用 LLM 提问部分代码如下,我们创建一个调用链来完成这个任务,稍后我们会详细讲解。
python
chain = setup_and_retrieval | prompt | model | output_parser如果知识库没有变化,我们并不需要每次都进行嵌入,而可以加载保存的向量库,然后直接检索。
提问部分详细代码
python
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_openai.chat_models import ChatOpenAI
from langchain_openai.embeddings import OpenAIEmbeddings
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
output_parser = StrOutputParser()
setup_and_retrieval = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
)
chain = setup_and_retrieval | prompt | model | output_parser
chain.invoke("where did harrison work?")
# result: 'Harrison worked at Kensho.'2. RAG 知识库创建详解
我们接下来用一个示例逐一详解如何用 LangChain 提供的工具创建一个知识库,并进行检索增强生成(RAG)
2.1 文档处理与向量库创建
2.1.1 加载文档
LangChain 提供了多种文档加载器(Document Loader)。它们可将各种文档加载成 Documents 对象,以便后续处理。
python
from langchain_community.document_loaders import TextLoader
loader = TextLoader(file_path)
docs = loader.load()
print(docs)
# [Document(page_content='\n\nWhat I Worked On\n\nFebruary 2021\n\nBefore college the two main things ……', metadata={'source': 'paul_graham_essay.txt'})]
len(docs)
# 1在这里,我们使用的是 TextLoader(Reference),你可以看到,它将整个文档加载成一个 Document 对象。
2.1.2 拆分文档
接下来,我们可使用 LangChain 提供的文档拆分功能,将文档拆分成一系列片段,以便后续处理。在代码中,我们设定了多个拆分参数。
python
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=500,
chunk_overlap=200,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.split_documents(docs)
len(texts)
# 157如上,我们使用 CharacterTextSplitter 拆分器,采用两个分行\n\n作为作为分隔符,并要求将长度拆分为 500 个字符一块。在这里,我们得到的是一个有着 157 个 Documents 元素的列表。
2.1.3 嵌入与存入向量库
接下来包括两步:首先,我们将 Documents 嵌入(Embedding)成向量,然后,将向量存入向量数据库,以备后续检索。借用 LangChain 的工具,我们可以一次性完成两个步骤:
python
from langchain_community.vectorstores import Chroma
from langchain_openai.embeddings import OpenAIEmbeddings
vectorstore = Chroma.from_documents(
documents=texts,
embedding=OpenAIEmbeddings(),
)这里,我们采用 OpenAI 的 Embedding 服务,并将向量存储到 Chroma 向量数据库。我们得到的是一个 vectorstore。
2.1.4 向量库查询
有了 vectorstore 之后,我们可以进行相似性查询:
python
query="what happened after the author switched to AI?"
results = vectorstore.similarity_search(query)
len(results)
#4,缺省检索出四个相关文档片段。2.1.5 向量库:存储与载入
以下两步是可选的,我们可将 vectorstore 存储,然后下次就不必再次进行嵌入。参考文档:langchain chroma
python
from langchain_community.vectorstores import Chroma
from langchain_openai.embeddings import OpenAIEmbeddings
# save to disk
vectorstore = Chroma.from_documents(
documents=texts,
embedding=OpenAIEmbeddings(),
persist_directory="./chroma_db"
)python
# load from disk
newdb = Chroma(
persist_directory="./chroma_db",
embedding_function=OpenAIEmbeddings(),)
query="what happened after the author switched to AI?"
results = newdb.similarity_search(query)
len(results)
#42.2 从向量库中检索
LangChain 的封装让向量库检索很便捷,如下:
python
retriever = vectorstore.as_retriever() # 将向量库设定为 retreiver
query="what happened after the author switched to AI?"
results = retriever.get_relevant_documents(query)
len(results)
#4
for doc in results:
print(doc)
# page_content="I couldn't have put this into words when I was 18. All I knew at the time was that I kept taking philosophy courses and they kept being boring. So I decided to switch to AI." metadata={'source': 'paul_graham_essay.txt'}……如上所示,我们可用相似性搜索从向量库中匹配文档,缺省为匹配 4 个文档片段。我们可以配置搜索参数 k 来调整数量。
python
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})实际上,在使用 LangChain 时,我们不必显式地做相似检索这一步,而可以调用链中一并设置。详见 2.3 小节。
2.3 RAG 调用链
在使用 RAG 时,我们将提问和文档片段组织成提示语,然后提交给 LLM 去进行生成。在使用 LangChain 时,调用链的结构如下:
代码如下:
python
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_openai.chat_models import ChatOpenAI
from langchain_openai.embeddings import OpenAIEmbeddings
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
output_parser = StrOutputParser()
setup_and_retrieval = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
)
chain = setup_and_retrieval | prompt | model | output_parser调用与结果
python
chain.invoke("where did harrison work?")
# Harrison worked at Kensho.调用过程解释如下:
- 提问被两路并行运行。其中一路去进行检索,结果作为
"context"。另一路用RunnablePassthrough(),作为"question" - 它们被输入提示语模板,形成给 LLM 的提示语。
- 模型返回后,解析为字符串。
如果你对调用链具体运转过程感兴趣的话,可以点开如下逐步调用链的逐步分析。
RAG 调用链逐步拆解
- 检索
python
setup_and_retrieval = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
)
print(setup_and_retrieval)
#result: steps={
# 'context': VectorStoreRetriever(
# tags=['DocArrayInMemorySearch'],
# vectorstore=<langchain_community.vectorstores.docarray.in_memory.DocArrayInMemorySearch object at 0x7b02f605fca0>),
# 'question': RunnablePassthrough()
# }检索结果
python
context_and_question = setup_and_retrieval.invoke("where did harrison work?")
print(context_and_question)
# {'context': [Document(page_content='harrison worked at kensho'),
# Document(page_content='bears like to eat honey')],
# 'question': 'where did harrison work?'}- 提示语模板
python
prompt_value = prompt.invoke(context_and_question)
prompt_value.to_messages()
# result: [HumanMessage(content=
# "Answer the question based only on the following context:\n[Document(page_content='harrison worked at kensho'), Document(page_content='bears like to eat honey')]\n\nQuestion: where did harrison work?\n")]- 模型调用
python
response = model.invoke(prompt_value)
print(response)
# result: content='Harrison worked at Kensho.'- 输出解析器
python
output_parser.invoke(response)
# result: 'Harrison worked at Kensho.'通过如上讨论,你已经可以了解 RAG 的基本工作原理。但是请注意,RAG 的关键并非仅仅是如上调用过程,关键是你构建的 RAG 管道的质量:
- 原始材料的质量及处理;
- 索引与检索的方式;
- 对检索结果质量的评估。
3. 小结
在本教程中,我们带你了解用 LangChain 实现 RAG 的基础过程。之后,你可以运用各种工具来组织的自己 RAG 调用链。