LangSmith 使用入门
LangSmith 是 LangChain 提供的 AI 应用开发监测平台,我们可以用它来观察调用链的运行情况。参考 LangSmith 文档 LangSmith Walkthrough, ,我们准备如下教程,你可以照着做来掌握如何使用它。
目录
1. 注册 LangSmith 与运行准备
要使用 LangSmith,你需要注册账号,并获得 LangChain API KEY。
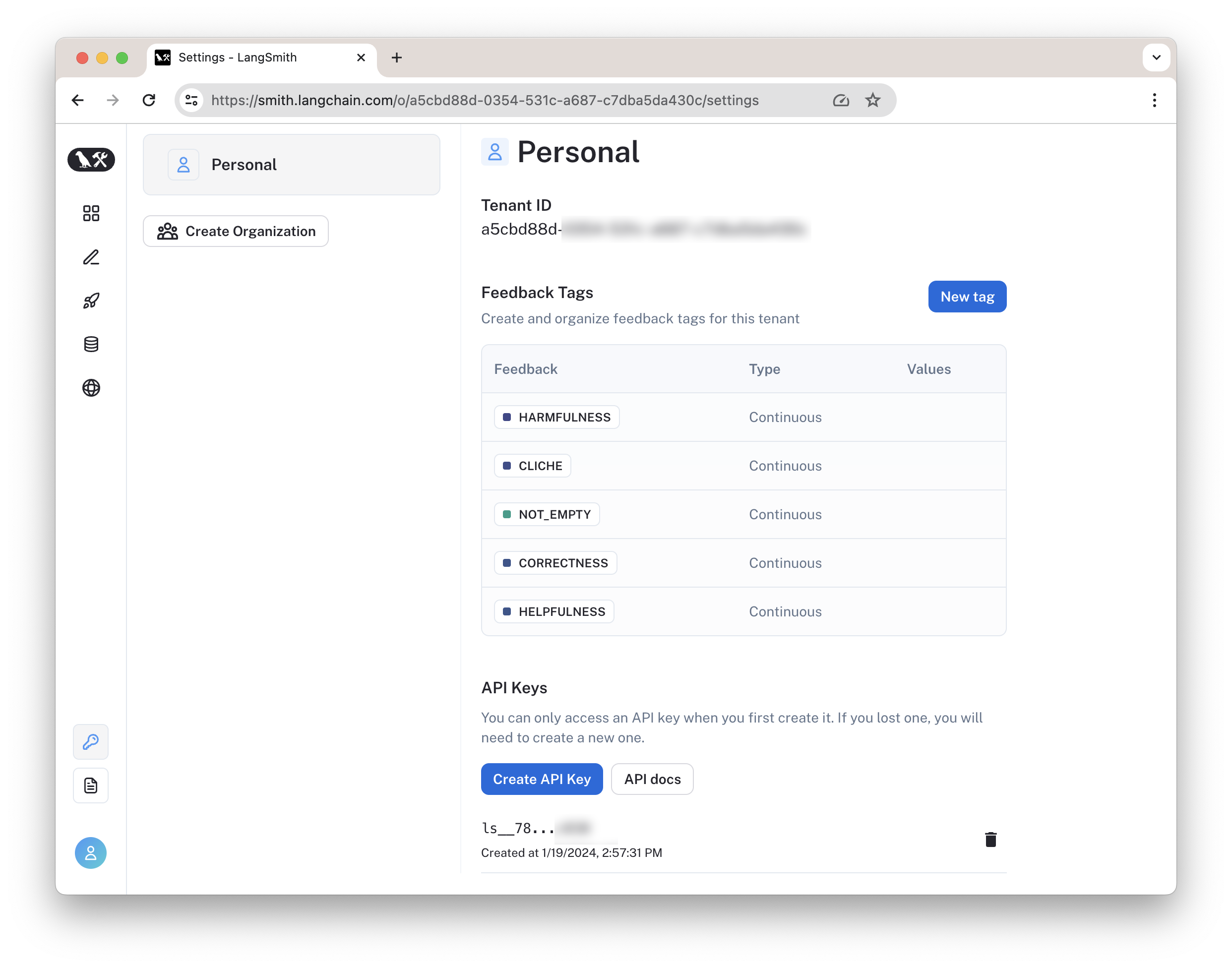
展开查看其他准备(安装依赖库,设置环境变量):
其他准备
- 安装依赖库
!pip install -U --quiet langchain-openai
!pip install -U --quiet langchain
!pip install -U --quiet langsmith langchainhub- 获取OpenAI key与LangChain API key
python
# only for this notebook author, please use input in the upside box
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('api_key')
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"LangSmith-start"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = userdata.get('langsmith')2. 记录运行日志
LangSmith 的常见用途之一是日志记录,我们用它记录 AI 应用的所有日志,并在事后查看。这一功能同样可以用于实际投入生产环境的 AI 应用。
python
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
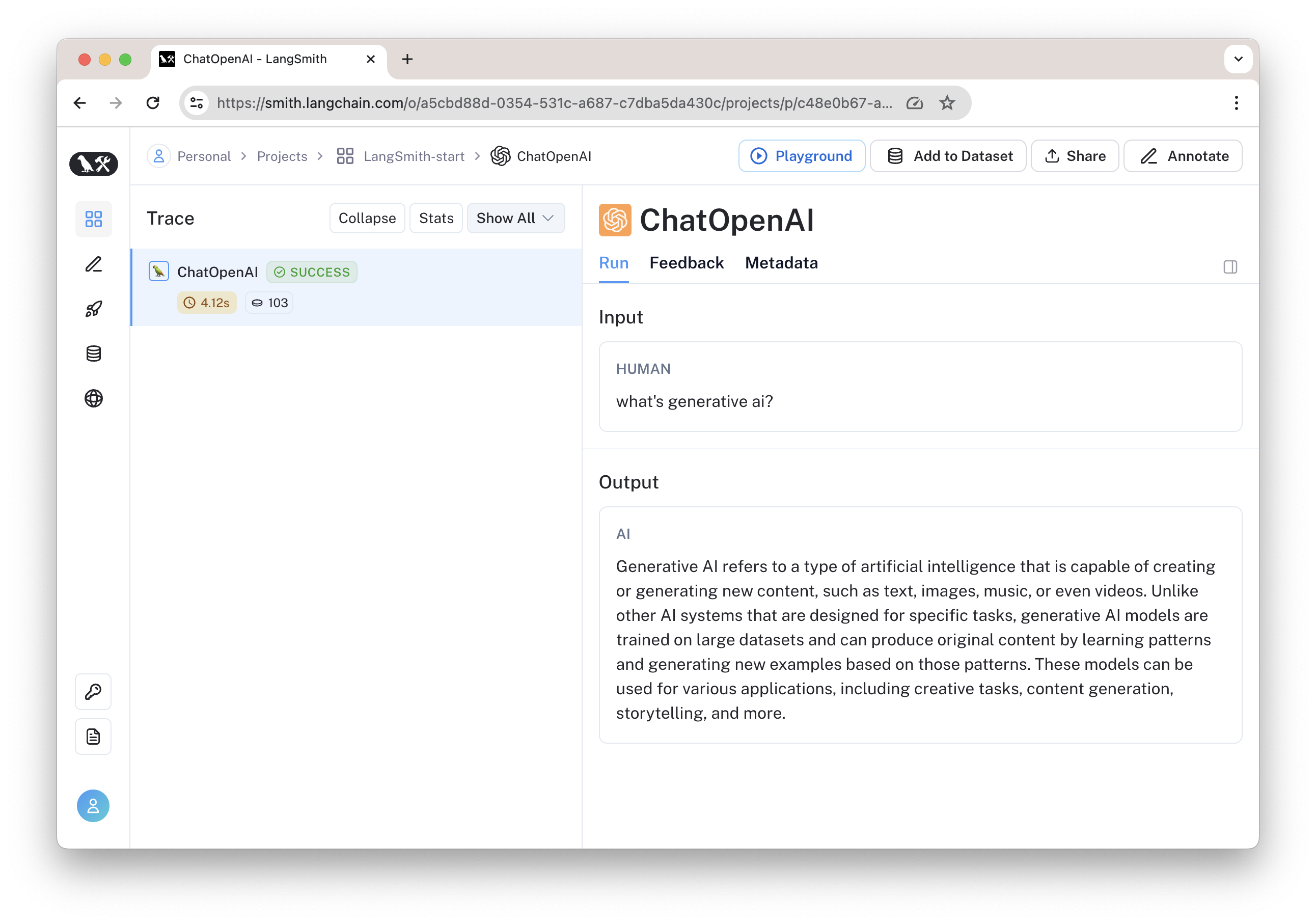
llm.invoke("what's generative ai?")输出: AIMessage(content='Generative AI refers to a type of artificial intelligence that is capable of creating or generating new content, such as text, images, music, or even videos. Unlike other AI systems that are designed for specific tasks, generative AI models are trained on large datasets and can produce original content by learning patterns and generating new examples based on those patterns. These models can be used for various applications, including creative tasks, content generation, storytelling, and more.')
这时,在 LangSmith 的 Projects 中,我们即可以看到自己设置的 "LangSmith-start"项目,并查看它的运行日志。
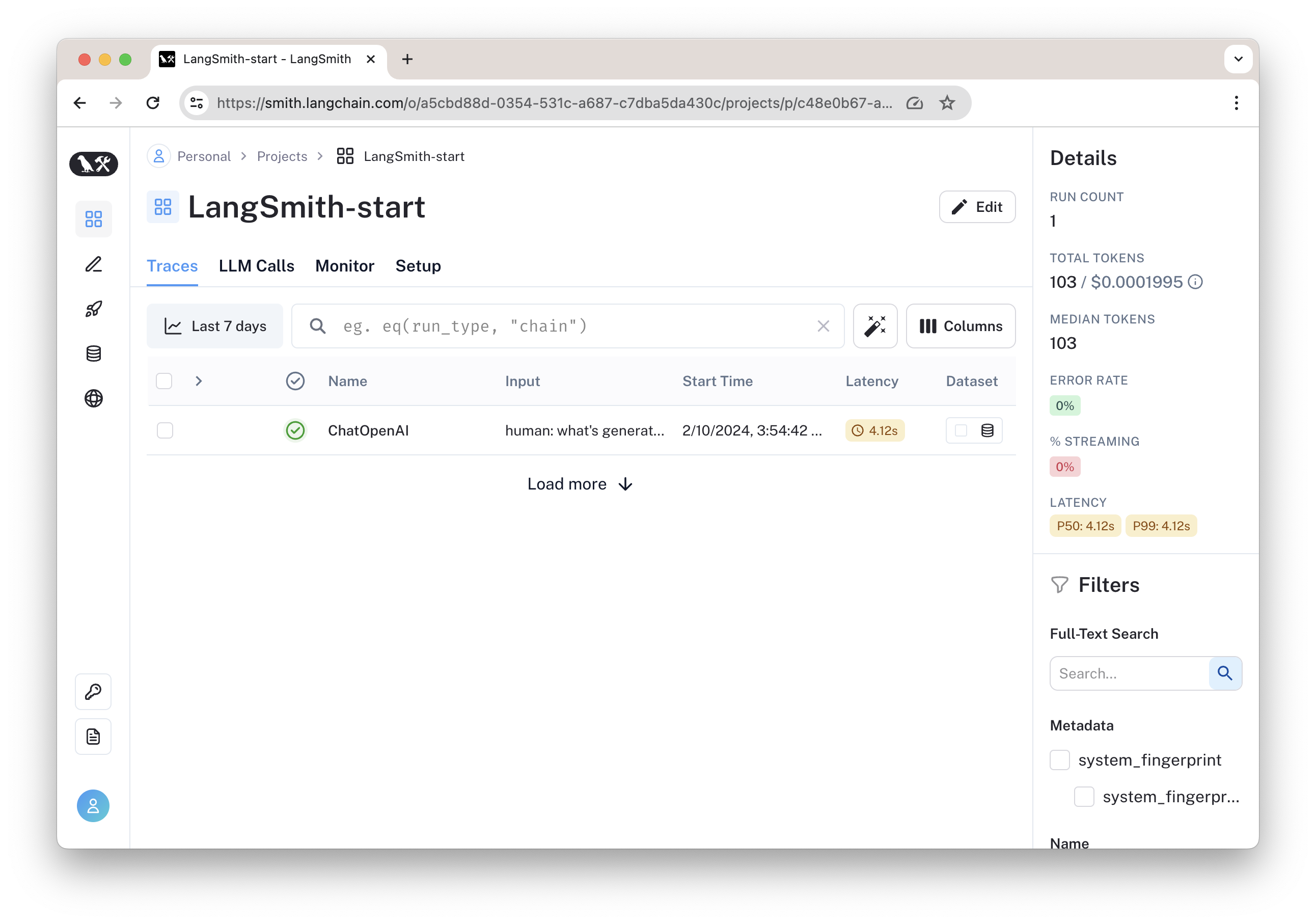
点击可以查看具体的运行结果,在这里可以看到输入与输出。
3. 记录运行日志:复杂版
我们运行如下两次调用模型的调用链,然后在 LangSmith 查看日志。
代码
python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from IPython.display import Markdown
llm = ChatOpenAI(
model_name="gpt-4-1106-preview"
)
prompt = ChatPromptTemplate.from_messages([
("system", "You are world class technical documentation writer."),
("user", "{input}")
])
translate_prompt = ChatPromptTemplate.from_messages([
("system", "Translate to simplified Chinese."),
("user", "{input}")
])
output_parser = StrOutputParser()
chain = prompt | llm | output_parser \
| {"input": RunnablePassthrough()} \
| translate_prompt | llm | output_parser
output = chain.invoke({"input": "what's generative ai?"})
display(Markdown(output))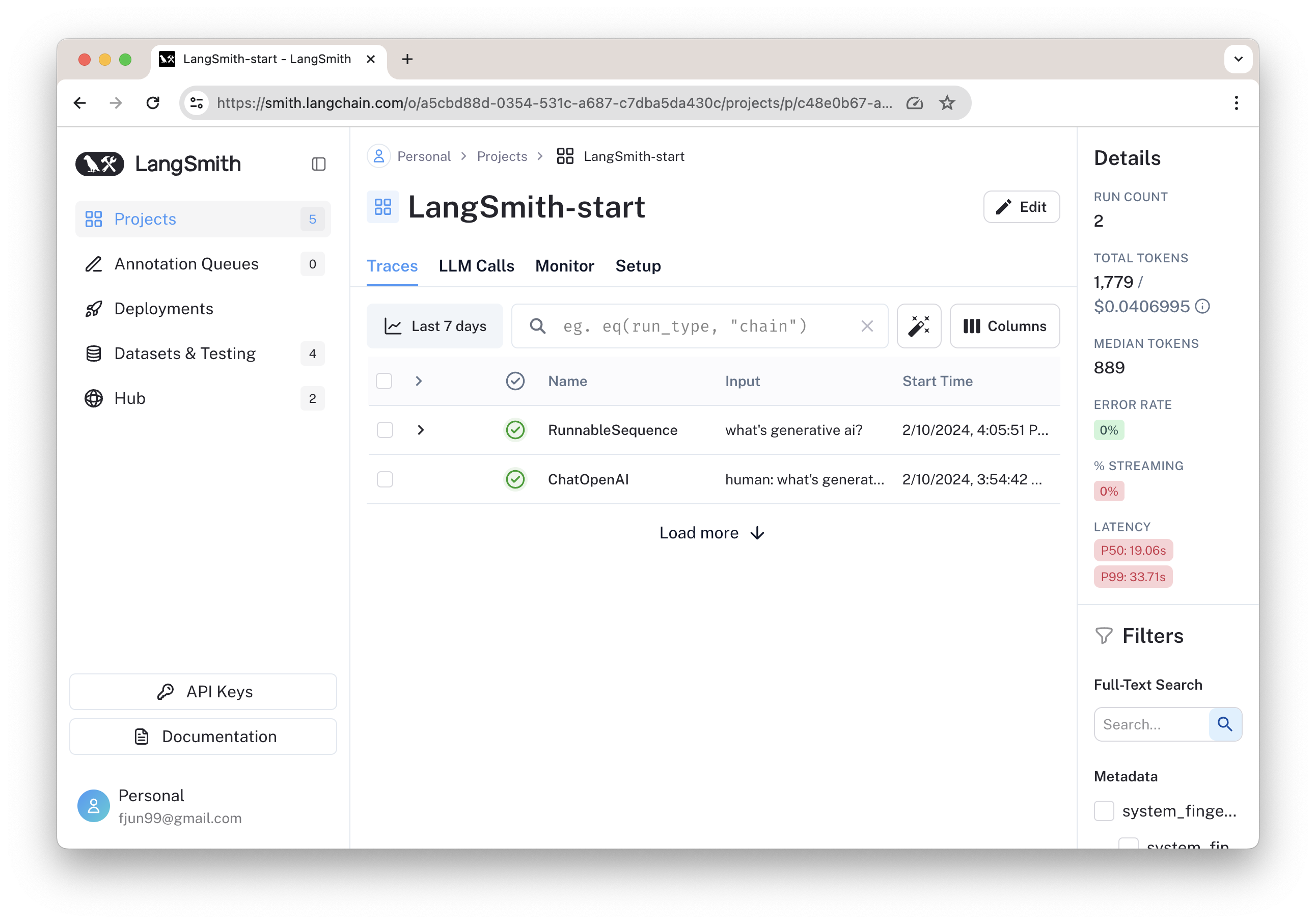
如下图所示,我们可以看到调用链的细节。 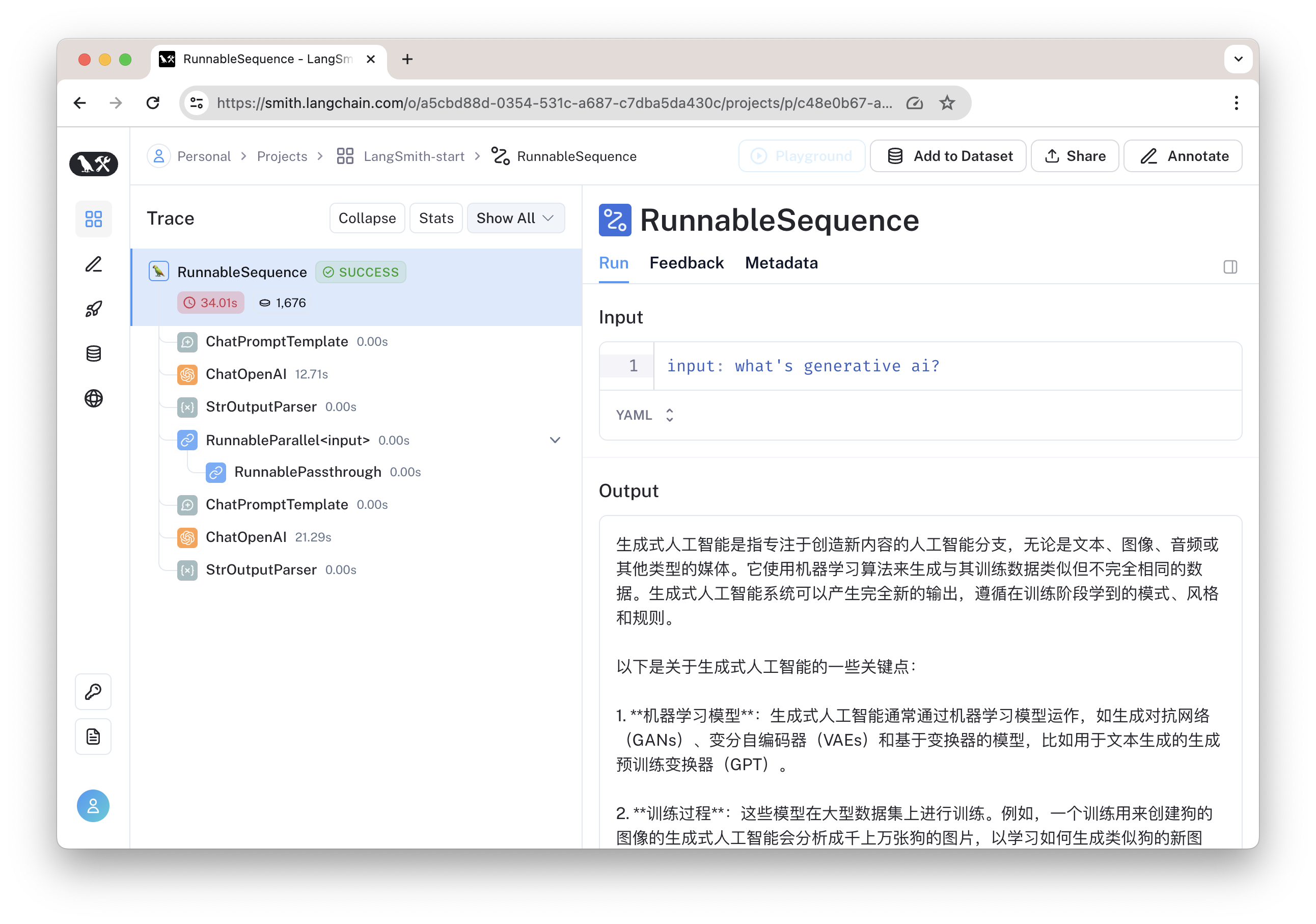
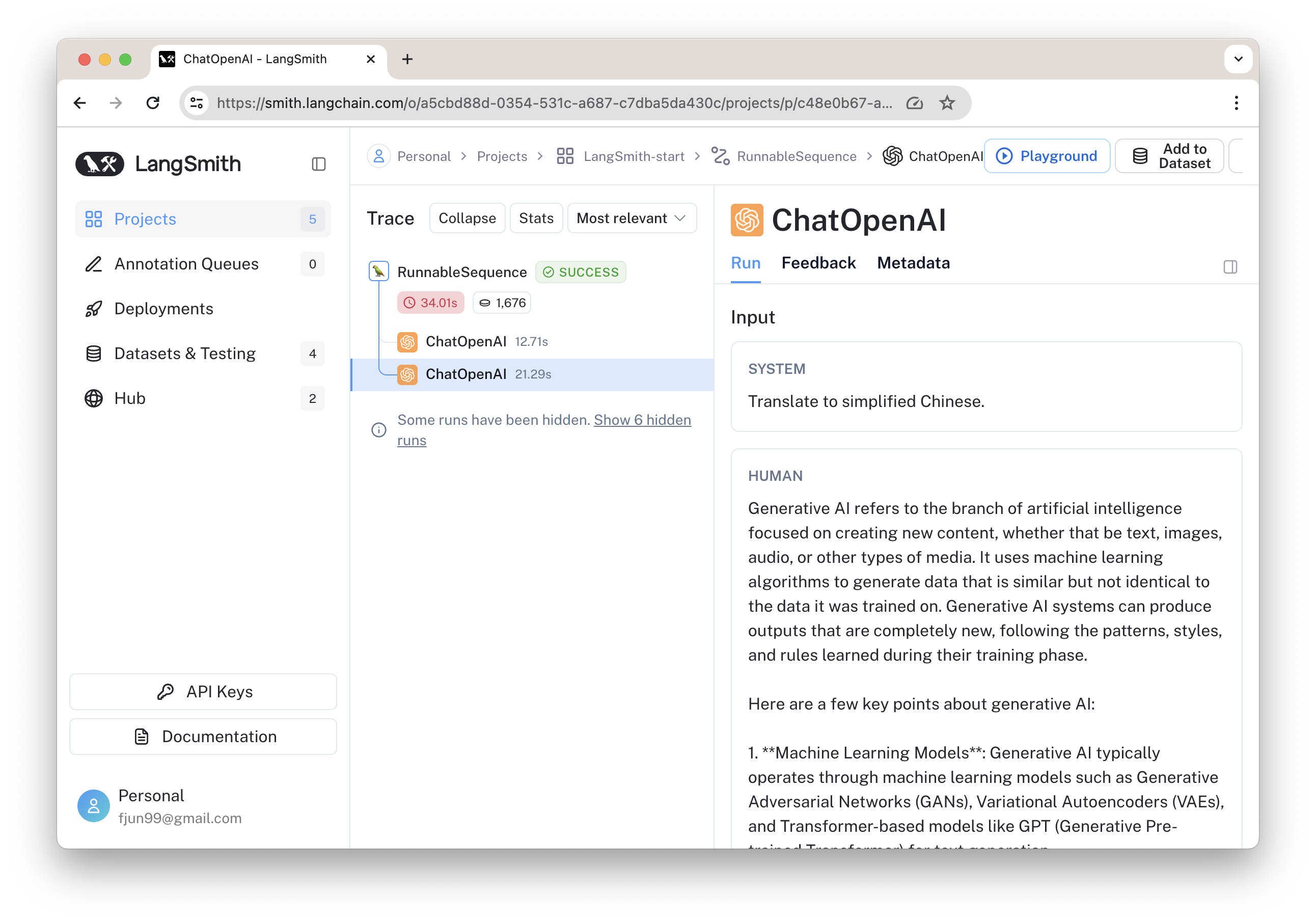
其中两次 ChatOpenAI 调用如下: 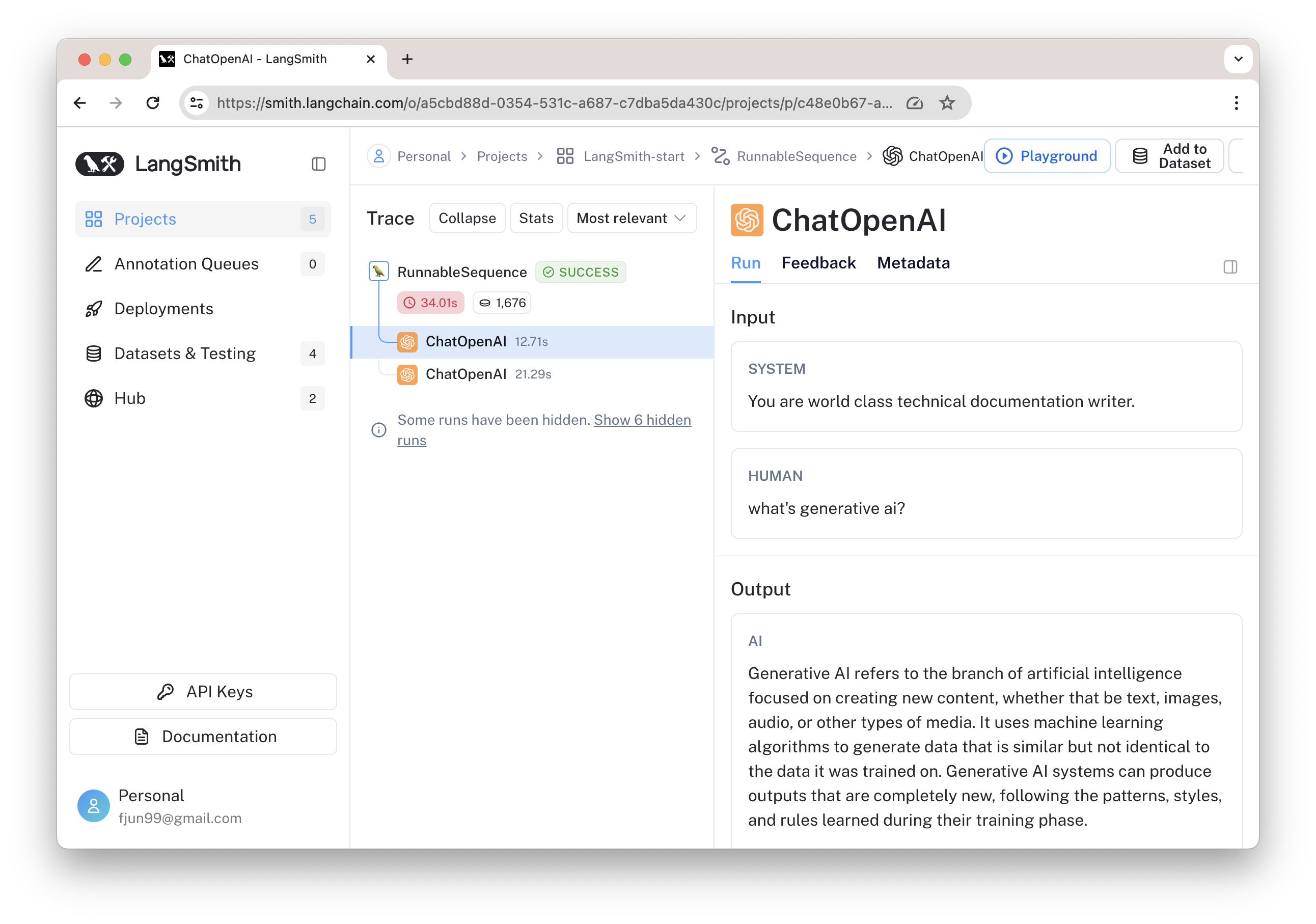
3. 进行提示语版本管理
LangSmith 为我们提供一个方便的功能 LangSmith Hub,我们可以用它来调试提示语。具体来说,它提供实用功能:
- 编辑提示语及提示语版本
- 类似Playground的提示语运行环境
- 在应用中加载提示语
- 与他人共享提示语
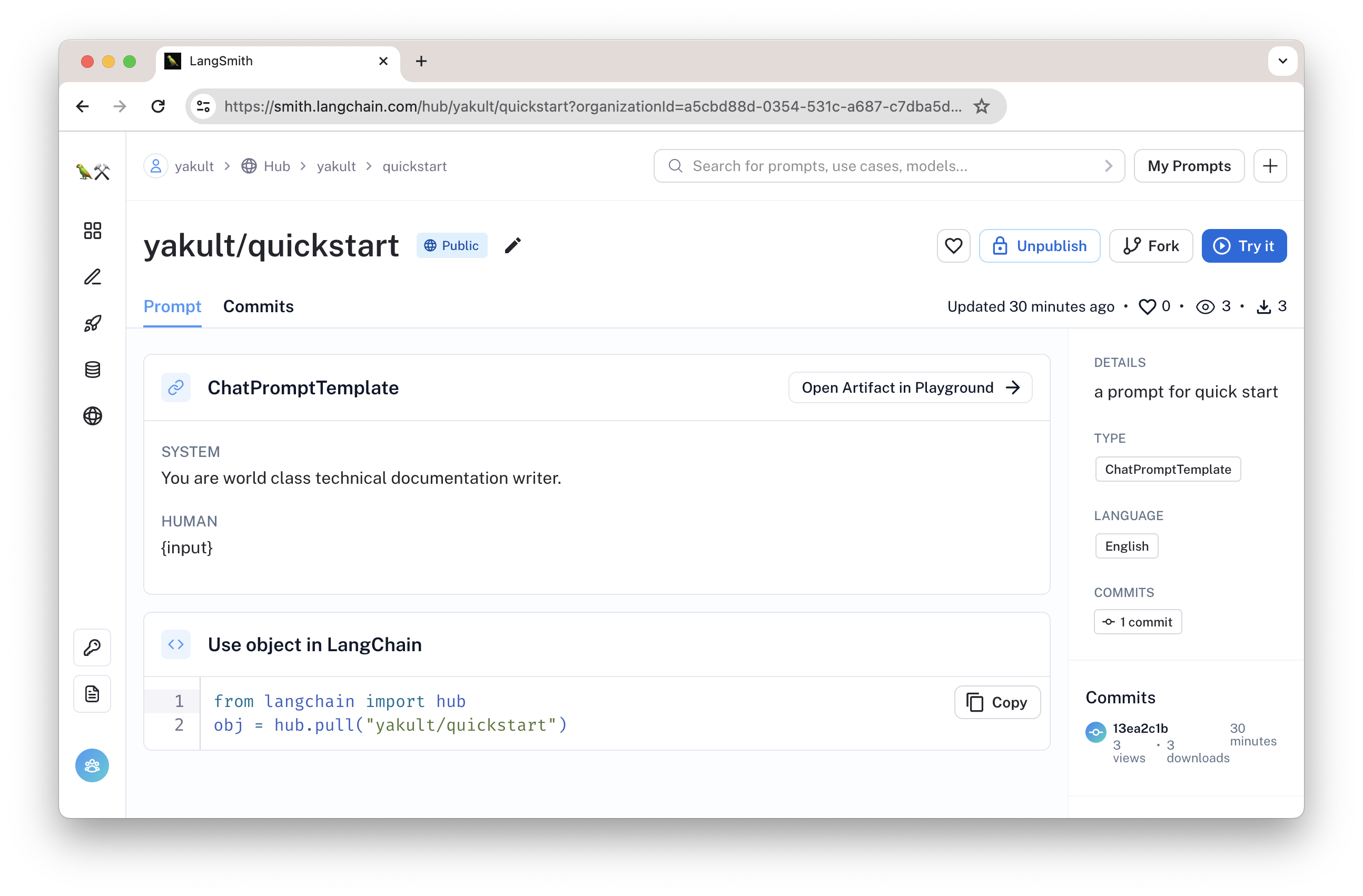
图:提示语
图示这一提示语的状态是 public,任何人都可以调用。你也可以设置私有提示语,仅有你自己可以使用。
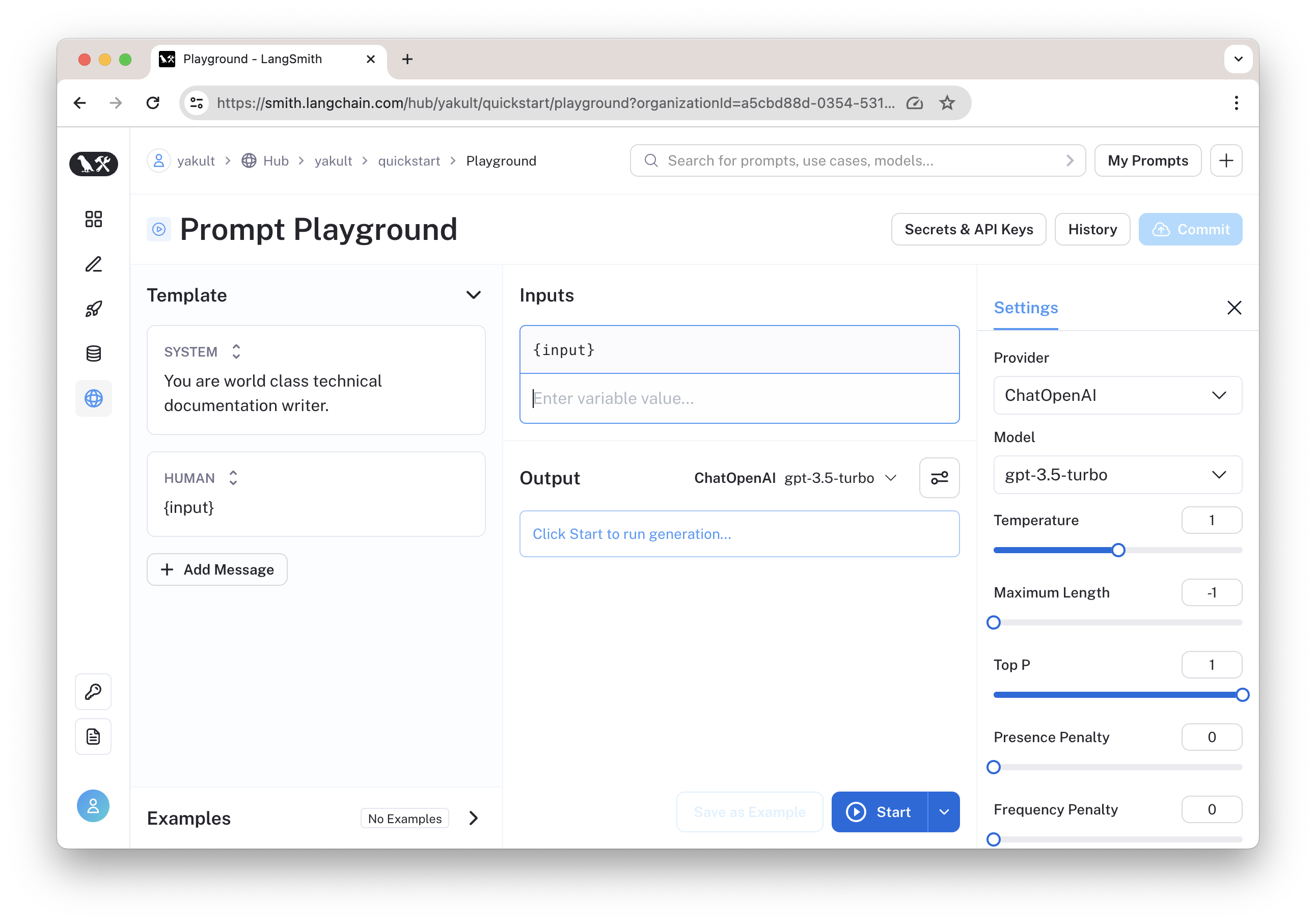
图:提示语 playground
在应用中加载提示语:
python
from langchain_openai import ChatOpenAI
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
prompt = hub.pull("yakult/quickstart") #加载提示语
llm = ChatOpenAI()
chain = prompt | llm | StrOutputParser()
output = chain.invoke({"input":"what's generative ai?"})我们可以加载特定版本的提示语,比如:
python
prompt = hub.pull("yakult/quickstart:c53fcc9d") #加载特定版本的提示语通常,我们在LangSmith Playground 调试提示语,将之 Commit 成不同的版本。
4. 在数据集上运行评估
LangSmith 的另一个常见用途是在数据集上运行评估。当我们开发一个 AI 应用的调用链后,我们要运行评估,以判断它是否符合预期。
LangSmith 集成了 LangChain 的评估功能,为我们提供了一个系统化的 AI 调用链评估工具:
- 开发一个 AI 应用的调用链(即业务逻辑)
- 在 LangSmith 创建数据集
- 在数据集上运行评估
- 在 LangSmith 界面查看评估结果
以下示例选自 LangSmith 测试与评估 中的调用链部分。略作修改,主要是增加部分解释。
4.1 开发一个 AI 应用调用链
python
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = ChatPromptTemplate.from_messages(
[("human", "Spit some bars about {question}.")]
)
chain = prompt | llm | StrOutputParser()这个提示语要求 AI 模型写几句说唱歌词,输入参数为question。
4.2 创建评估数据集
我们可以用如下代码创建数据集,但更方便的方式是直接在 LangSmith 界面中直接创建。
python
from langsmith import Client
# Inputs are provided to your model, so it know what to generate
dataset_inputs = [
"a rap battle between Atticus Finch and Cicero",
"a rap battle between Barbie and Oppenheimer",
# ... add more as desired
]
# Outputs are provided to the evaluator, so it knows what to compare to
# Outputs are optional but recommended.
dataset_outputs = [
{"must_mention": ["lawyer", "justice"]},
{"must_mention": ["plastic", "nuclear"]},
]
client = Client()
dataset_name = "Rap Battle Dataset-0210"
# Storing inputs in a dataset lets us
# run chains and LLMs over a shared set of examples.
dataset = client.create_dataset(
dataset_name=dataset_name,
description="Rap battle prompts.",
)
client.create_examples(
inputs=[{"question": q} for q in dataset_inputs],
outputs=dataset_outputs,
dataset_id=dataset.id,
)如上代码将创建一个评估数据集,其中一条数据如下图。在其中我们可看到输入与输出。
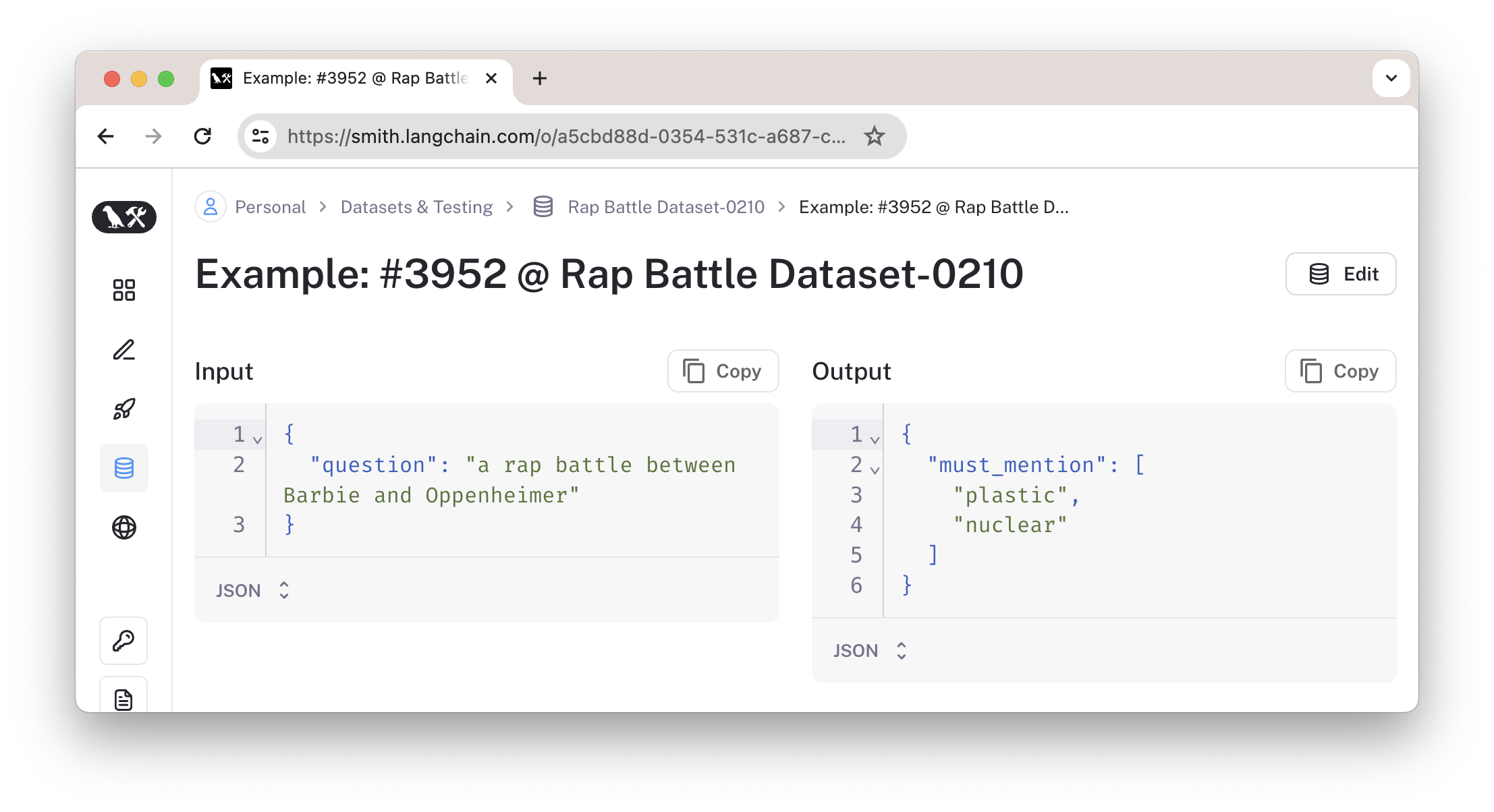
4.3 创建评估
我们用 LangSmith 创建要运行的评估。以下评估中包括两个标准:一是自定义的评估标准must_mention,要求判断AI应用是否包含相应的短语;二是CriteriaEvalChain的自定义,要求判断回答是否俗套。
python
from langchain.smith import RunEvalConfig, run_on_dataset
from langsmith.evaluation import EvaluationResult, run_evaluator
@run_evaluator
def must_mention(run, example) -> EvaluationResult:
prediction = run.outputs.get("output") or ""
required = example.outputs.get("must_mention") or []
score = all(phrase in prediction for phrase in required)
return EvaluationResult(key="must_mention", score=score)
eval_config = RunEvalConfig(
custom_evaluators=[must_mention],
# You can also use a prebuilt evaluator
# by providing a name or RunEvalConfig.<configured evaluator>
evaluators=[
# 自定义 CriteriaEvalChain
RunEvalConfig.Criteria(
{
"cliche": "Are the lyrics cliche? Respond Y if they are, N if they're entirely unique."
}
),
],
)用如下代码运行评测,注意修改相应的 "project_name"。
python
client.run_on_dataset(
dataset_name=dataset_name, # 评估数据集
llm_or_chain_factory=chain, # 调用链
evaluation=eval_config, # 评测
verbose=True,
project_name="runnable-test-0210",
# Any experiment metadata can be specified here
project_metadata={"version": "1.0.0"},
)4.4 查看评估结果
我们可在 LangSmith 界面中查看评估结果,如下图所示。
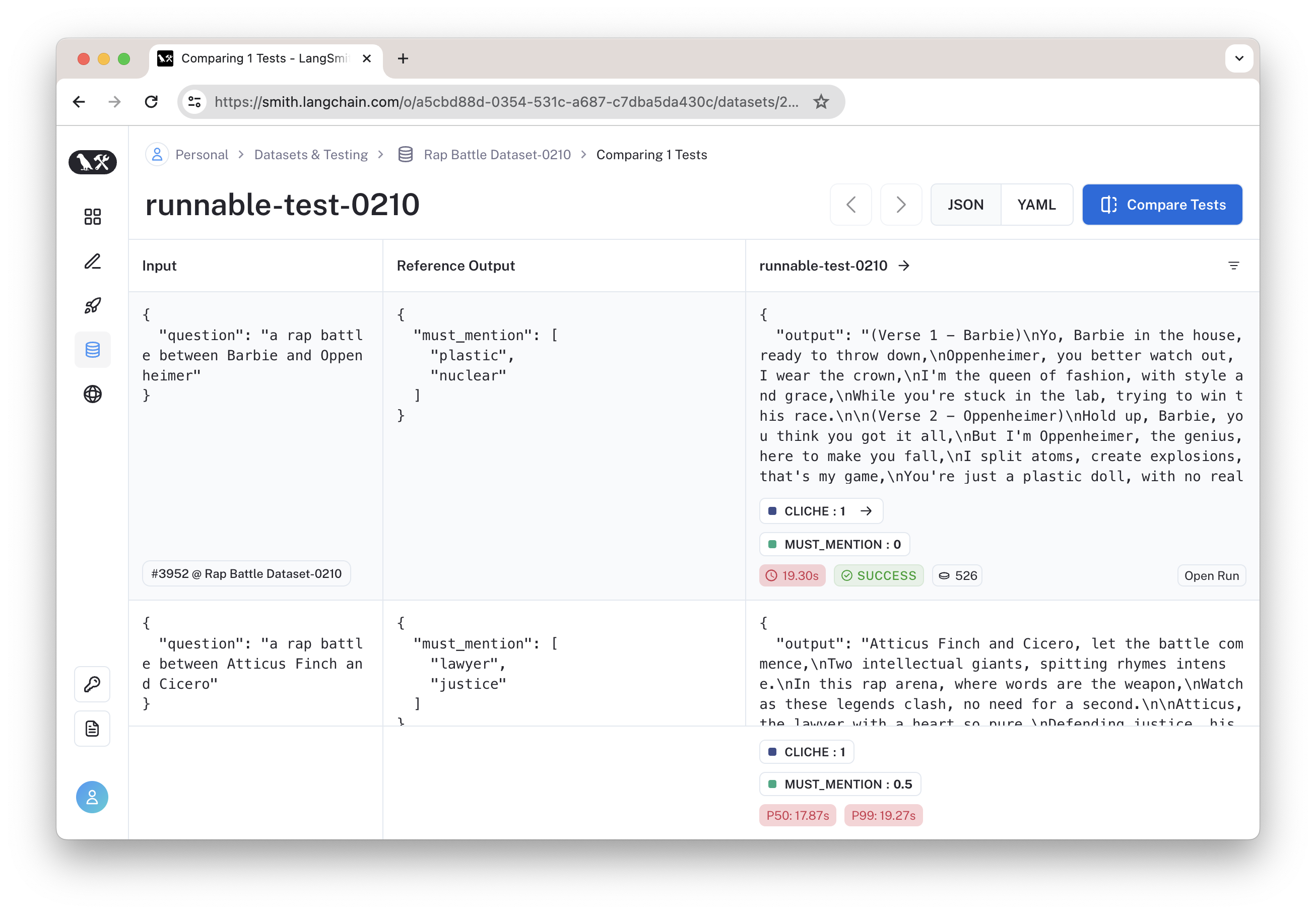
其中的 Cliche 是由 AI 模型完成的,在 LangSmith 可看到其调用过程如下:
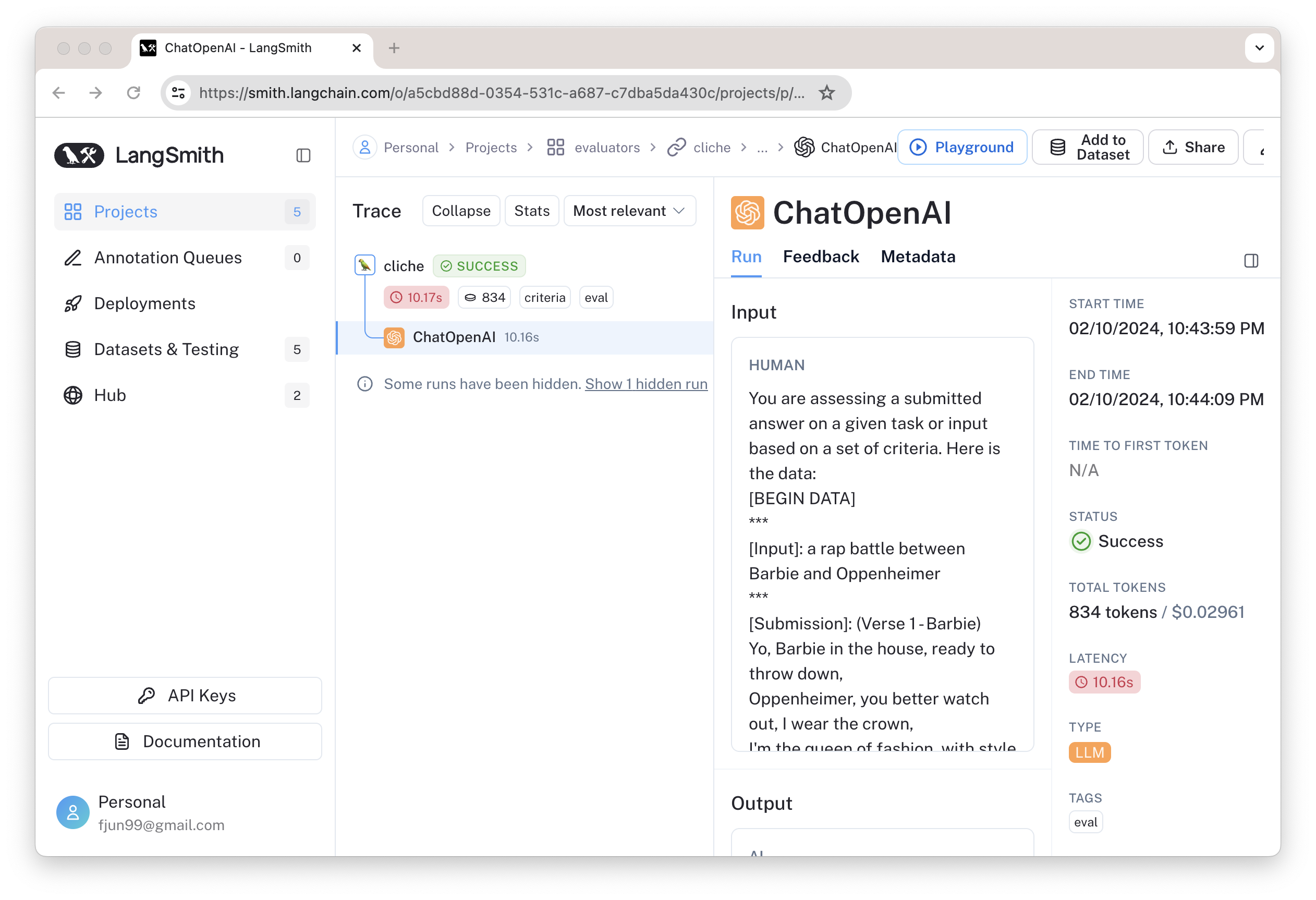
其中输入是:
You are assessing a submitted answer on a given task or input based on a set of criteria. Here is the data:
[BEGIN DATA]
***
[Input]: a rap battle between Barbie and Oppenheimer
***
[Submission]: (Verse 1 - Barbie)
Yo, Barbie in the house, ready to throw down,
Oppenheimer, you better watch out, I wear the crown,
I'm the queen of fashion, with style and grace,
While you're stuck in the lab, trying to win this race...
***
[Criteria]: cliche: Are the lyrics cliche? Respond Y if they are, N if they're entirely unique.
***
[END DATA]
Does the submission meet the Criteria? First, write out in a step by step manner your reasoning about each criterion to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character "Y" or "N" (without quotes or punctuation) on its own line corresponding to the correct answer of whether the submission meets all criteria. At the end, repeat just the letter again by itself on a new line.输出是:
The criteria asks if the lyrics are cliche. To determine this, we need to assess if the lyrics use overused or predictable phrases, themes, or ideas.
Looking at the lyrics, we can see that they use common themes and ideas found in many rap battles. For example, each character is boasting about their own accomplishments and belittling the other's. This is a common theme in rap battles.
Additionally, the lyrics use some predictable phrases. For example, Barbie refers to Oppenheimer as a "nerd" and Oppenheimer refers to Barbie as a "plastic doll". These are predictable insults given the characters involved.
Therefore, based on the use of common themes and predictable phrases, the lyrics can be considered cliche.
Y
Y5. 小结
通过如上讨论,我们可以看到,LangSmith 为我们观测 AI 应用提供了多种便利的工具,这同样能加速 AI 应用的开发。
参考资料:
- LangSmith Introduction https://docs.smith.langchain.com/
- LangSmith Walkthrough Notebook https://python.langchain.com/docs/langsmith/walkthrough